Stable Diffusion检索流程
注意修改路径
-
7.28测试 跑分为0
- 使用
generate_img.py每一个topics生成1000张图片作为查询模拟
- 30 topics 分4个程序跑需要10h
-
生成的图片符合语义
-
feature_extractor.py使用CLIP的ViT-B/32提取每个生成图片的特征向量并保存
-
- 2个topics,每个topic有1000张图片 9min10s,大概5h
-
找一张图片的特征向量和数据集的特征向量计算并排序,看看top10
- 7.29测试 top5没有问题
-

-
compute_score.py使用faiss加速计算生成图片与数据库图片的相似度。
-
- 2个topics ——1h13min 总的 15h
-
大概率问题出在这里。
- 是faiss计算的结果并不是相似度,而是一个给分,分数越大,相关性越低,所以应该升序排序,
sorted()函数内不该加reverse = True-
merge_result_prob.py将所有txt文件合并成一个txt文件用作计算指标
-
- 是faiss计算的结果并不是相似度,而是一个给分,分数越大,相关性越低,所以应该升序排序,
- 使用
-
perl_to_excel.py计算指标
-
7.29 23:47 测试成功!终于到正常水平了。
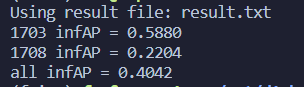
- 20topics——20x35min~11h40min 明天中午12点,明天可以想想4个优先级的提交思路,和老师汇报一下,或者改一下交互算法。
This line appears after every note.
Notes mentioning this note
Projects
0.百科全书
[[github问题]] 2024.10.08
[[笔记本电脑]]
[[华为手机安装google框架]]
[[科研问题]]
[[github问题]]
[[huggingface]]
[[linux]]
[[Python使用]]
[[Vscode使用]]
[[港科广二期HPC使用]] 2025.07.25
[[顶会论文及检索网址]] 2025.10.10
1.前后端
[[使用Flask快速构建浏览器实现图片交互]]