Improving interpretable embeddings for ad Hoc video search with generative captions and multi Word concept bank
* Authors: [[ Jiaxin Wu ]], [[ Chong-Wah Ngo ]], [[ Wing-Kwong Chan ]]
- DOI: 10.48550/arXiv.2404.06173
***
文章理解
现存问题
- 视频-文本数据集规模小
- concept bank 质量低,导致查询不可处理或者不被概念库包含
- 大数据集一个视频只有一条注释,忽略内容丰富性
- 现有的概念库方法都是word级别的,在建模关系时容易受word之间的影响,比如“手托脸”这种位置关系
相关工作
AVS的主流方法:基于概念库和基于特征 ITV(interpretable embedding model):引入概念编码器,将视觉特征和文本特征转换成 $[𝑝_1 ,𝑝_2, …,𝑝_𝑛]$ 的形式,代表了概念和其对应概率。
主要方法
-
利用生成式模型,构建大规模文本-视频数据集WebVid-genCap7M,利用到的是BLIP生成的。

- 构建多词概念库,利用句法分析,来源于视频注释的句法分析(名词、动词、形容词、介词、量词)
- 调研最先进的特征方法
- 文本编码器:CLIP,BLIP-2,imagebind(CVPR2023)
\(𝐹(𝑥) =𝐵𝑁(𝐹𝐶([CLIP, BLIP-2, imagebind]))\)
- 视觉编码器
实验结果
问题
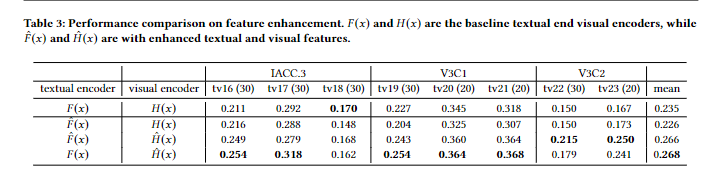
- 为什么新文本和新视频编码器在V3C1和IACC.3数据集上表现比不过旧的文本编码器加新视觉编码器的组合
感想
其实在实验上似乎并没有达到大幅度地最佳,比如相比SOTA方法多了0.01或者0.003,而且很多实验结果没有很好地解释。但是文章的表达我觉得值得我学习,很多英文句子一读就很地道。对于ITV这个方法,我觉得它在结合概念库和嵌入的方法上,似乎还有提升空间?但是为啥是用特征提取概念,而不是更原始的图片和文本来提取概念?
This line appears after every note.
Notes mentioning this note
Paper Reading
0. Solid Ideas
Yoshua Bengio重新思考ML的投稿
1.Quantum Computing
[[TKDE’16_Relevance Feedback Algorithms Inspired By Quantum Detection]]