Icml'25 forest Of Thought scaling test Time compute for enhancing llm reasoning
ICML’25 Forest-of-Thought Scaling Test-Time Compute for Enhancing LLM Reasoning
作者:Zhenni Bi † Kai Han † Chuanjian Liu Yehui Tang * Yunhe Wang * 机构:华为诺亚方舟实验室
文章理解
引言
之前工作的缺点:
- 使用更丰富的提示或者将复杂问题分解为简单的子问题,如果初始路径有缺陷,也不会审视其他有可能的方法
- 可能忽视细节或者在中间步骤出错 解决方法:
- 参考人类从多个角度重复反思和验证,设计FoT,融合多个推理树来进行集体决策,同时每个树使用稀疏激活策略选择最相关的路径
- 动态自纠正策略,结合实时纠正和历史学习
- consensus-guided decision-making strategies共识指导决策策略确保模型只在需要的时候继续推理过程
相关工作
- XoT Reasoning
- CoT:step-by-step reasoning,面对复杂问题时效果不佳,因为解题思路往往是多维非线性的
- LtM(Least-to-Most Promoting):将复杂的问题分解为更简单的任务,比如将推理问题转化成一系列的编程问题求解,降低了token消耗
- ToT:对于复杂问题,树的深度可能过大,使搜索空间指数级别增加。GoT使用图结构而非树。SoT先生成答案的大纲,然后并行完成内容。
- MCTS:它通过随机模拟(推出)评估节点,并逐步构建本地游戏树,以在有限的时间内识别最佳或近乎最佳的解决方案。
方法
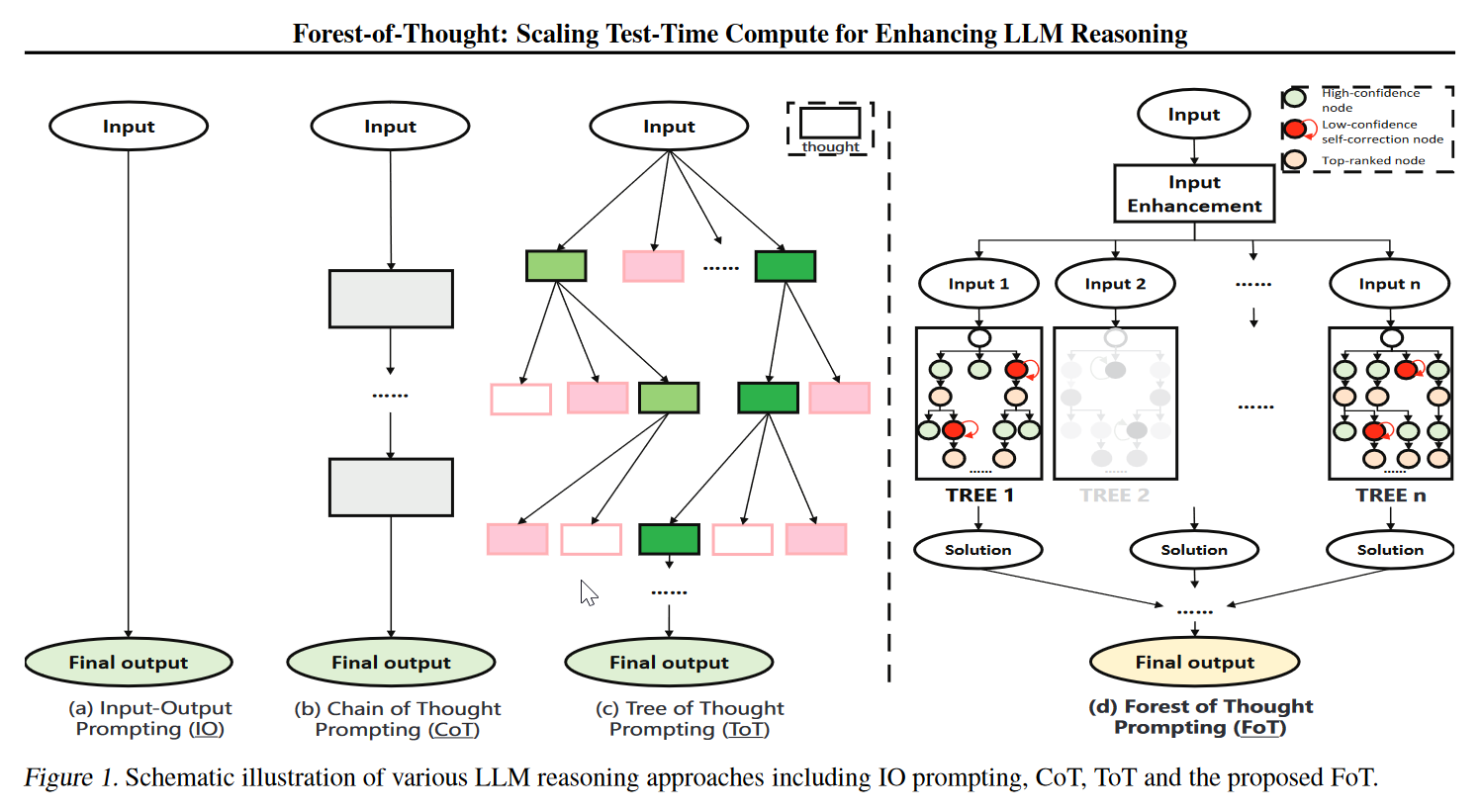
这个方法有n个推理树,每个树从不同角度输入问题。以稀疏激活的方式考虑这些树的结果,同时通过决策策略产生高质量的响应。此外,提出了一种动态自我纠正策略来提高准确性。
稀疏激活确保选择最相关的推理树进行计算。对于每个树的每一层,我们选择得分最高的节点进行下一步推理,如果树没法给出有效输出,则提前终止这个树的扩展。
“面对复杂的问题时,我们的认知过程通常会从快速,直观的“快速思考”转变为更深入,更系统的‘缓慢思考’”。构建知识库B支持推理过程,通过检索知识库B中最相关的问题来引入额外知识。
方法动态评估每个推理步骤,当分数低于阈值,自动矫正和修复误差。
Consensus-Guided Expert Decision (CGED),交给LLM专家指导推理过程。每个激活树都生成了最佳解决方案,通过共识投票和专家评估确定最终答案。
实验
LLM reasoning benchmarks:Game of 24、GSM8K、 MATH Model : Llama3-8B-Instruct、Mistral-7B、GLM-4-9B
Game of 24
每个策略进行消融实验

相同计算资源下的准确率
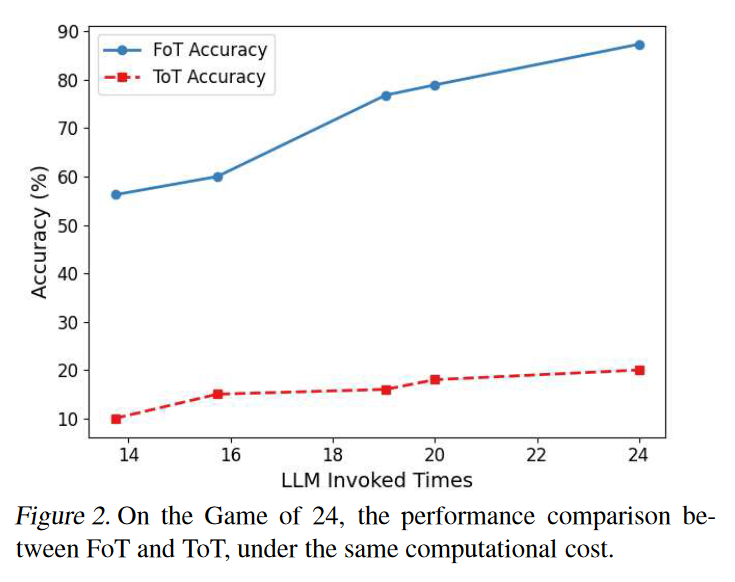
GSM8K
不同参数设置下的实验
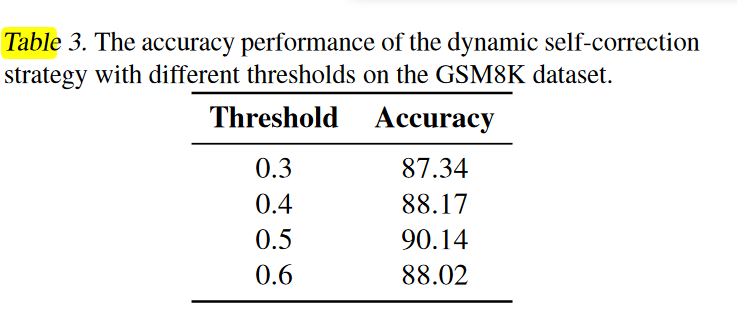
自动矫正最佳阈值实验
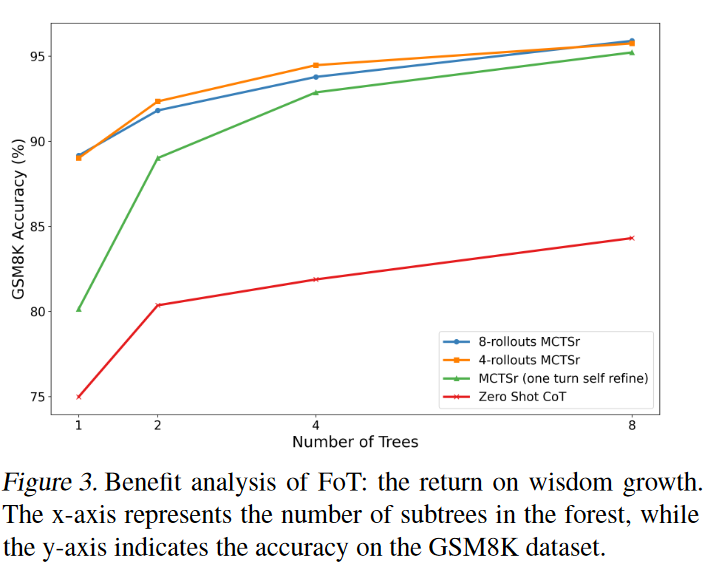
子树越多,准确率提升越大
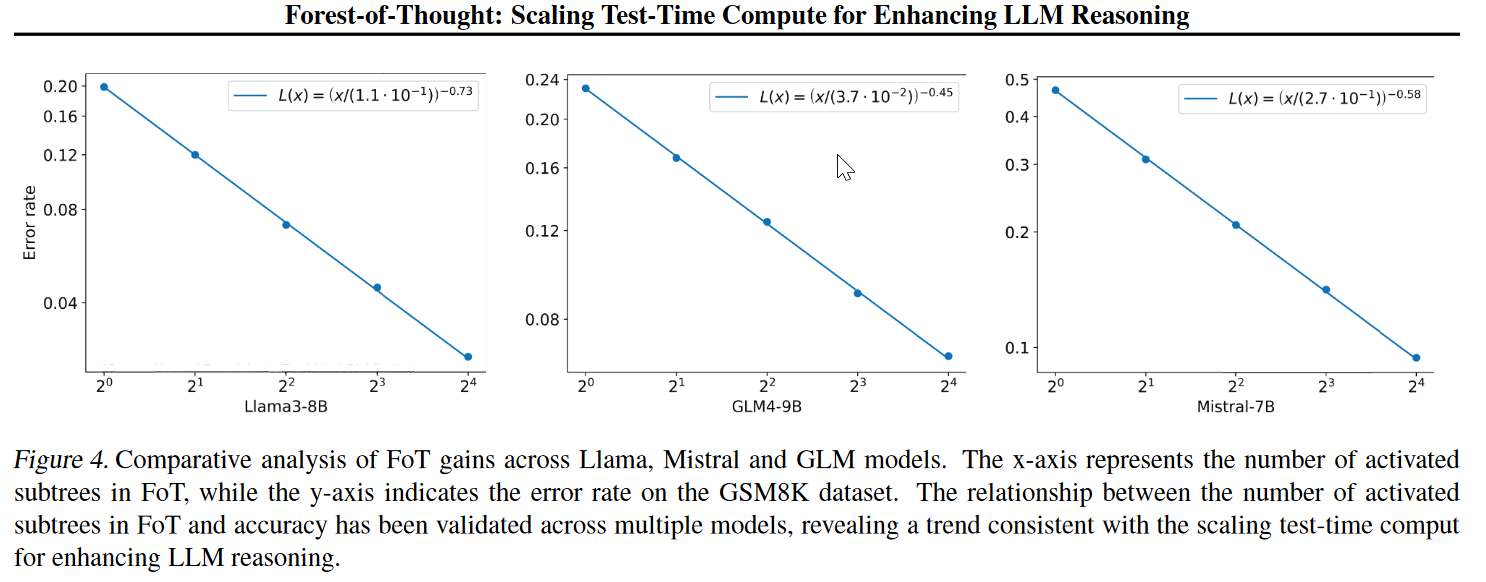
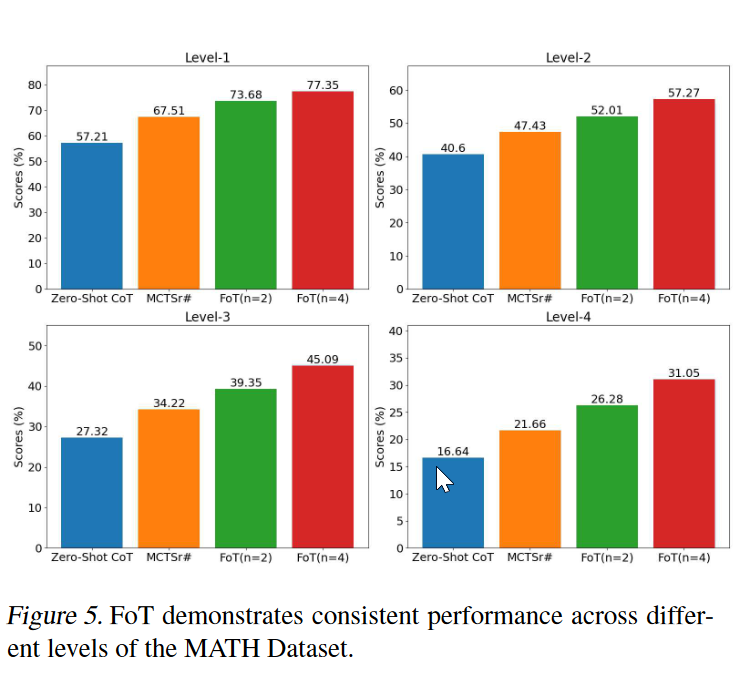
MATH
不同难度下的表现
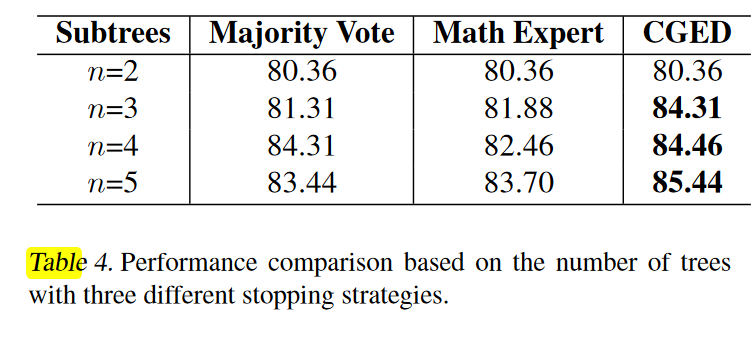
早停策略的消融实验
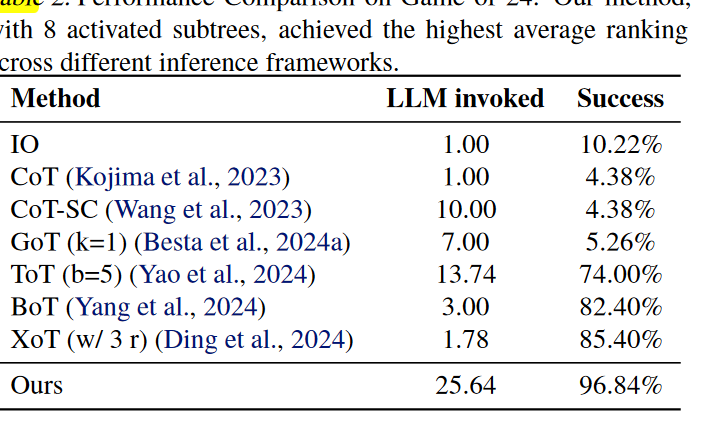
Main results
在Game of 24 与各种主流方法的对比
在三个不同难度的数据集上实验,证明方法增强模型性能的有效性。
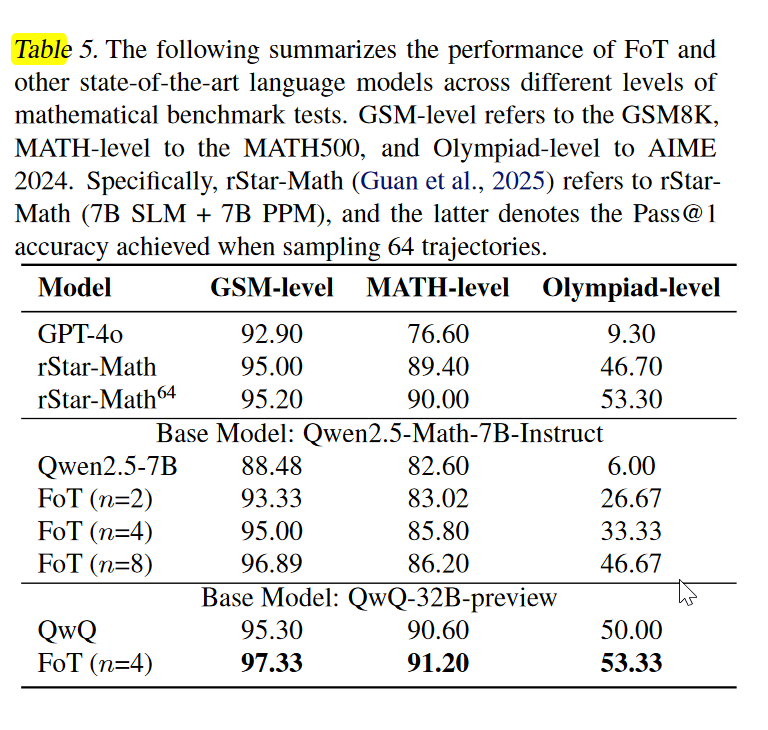
自己的感悟
- 消融实验充分,但是我很好奇是怎么保证计算资源相同的,同时我对最后一个实验的动机有疑问,为什么使用Qwen和QwQ,以及和rStar-MATH对比的原因是什么,像是reviewer说了然后补充的实验。
- 好像比较流行从算法上面迁移一些思路到LLM运用上,还有必要现在学算法吗。
工作扩展
This line appears after every note.