Icml'25 cogmath assessing llms’ authentic mathematical ability from a human cognitive perspective
ICML’25 CogMath Assessing LLMs’ Authentic Mathematical Ability from a Human Cognitive Perspective
作者:Jiayu Liu 1 2 Zhenya Huang 2 3 Wei Dai 1 Cheng Cheng 2 3 Jinze Wu 2 4 Jing Sha 2 4 Song Li 2 4 Qi Liu 1 2 Shijin Wang 2 4 Enhong Chen 2 3
机构:中国科学技术大学
文章理解
引言
Facts:
- GPT-4在高中数学难度的MATH数据集达到75的准确率
- o1在AIME达到70%+
典型dataset:
- E-GSM:需要四步推理长度的问题
- GSM-Plus:八个GSM8K数据集的变体
- MPA:基于五个原则重写数据集
之前工作的缺点:
- 之前的工作都是针对特定任务的,如长文本理解
- 总是看粗粒度的准确度测量,而不能捕捉LLM的全部数学能力 解决方法:
- 借鉴人类推理过程时的认知阶段,设计了九个测试维度
- problem comprehension
- problem solving
- solution summarization:引入中间问题和反向推理任务,测试模型是否可以通过推理途径追溯
- 设计了一个多agent系统“Inquiry-Judge-Reference”,针对问题询问九个维度的查询确保模型完全掌握
- 提出特定维度查询
- 完善查询来确保质量
- 提供正确答案作为参考
- 将CogMath应用于GSM8K和MATH以及自创数据集MExam,测试七个主流模型
论文贡献:
- 模型真实的数学能力其实被高估30%
- 模型参数量和推理阶段的挣扎是有联系的
- 现存的COT和ICL无法真正提高LLM达到数学推理能力
相关工作
LLM
- Base Model
- COT、ToT、GoT
- ICL
- RAG
Benchmark
根据难度分类
- 高中:MATH CHAMP
- 小学: GSM8K MAWPS 根据问题类型分类
- 在长文本上的生成能力
- 证明和应用定理:TheoremQA MathBench
- 视觉和几何推理:MathVista
- 减轻数据污染:GSM-1k、GSM-Plus、MPA
详细内容
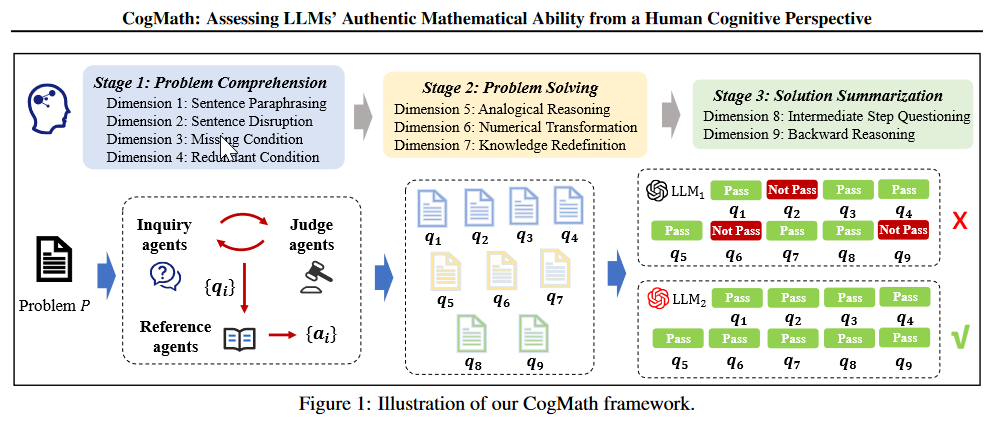 作者参考了心理学上有关人类推理的理论,提出三个阶段,九个维度。针对每个维度使用multi-agent系统获取问题和答案
作者参考了心理学上有关人类推理的理论,提出三个阶段,九个维度。针对每个维度使用multi-agent系统获取问题和答案
- Problem comprehension
- sentence paraphrasing :改变措辞和句式结构,保留数学本质
- ==sentence disruption ==:避免模型单纯记住问题和答案,随机破坏单词顺序,从人类角度是不可读的,预期的相应是无法解决,如果与原始答案相同表明可能是记忆答案而非理解问题。(很骚的操作,但是LLM从原理上来说很难避免?)
- missing condition:去掉一些条件问题不可解
- Redundant Condition:引入冗余条件,judge代理需要确保冗余条件不影响问题求解。
- Problem solving
- Analogical Reasoning:人类可以用相同的解题步骤举一反三。在不改变难度的情况下出新题
- Numerical Transformation:修改初始问题数值
- Knowledge Redefinition:创建一个新的定义(可能和现实违背),用新定义来解题。(对Reference Agent要求较高?)
- Solution Summarization
- Intermediate Step Questioning.:询问关键中间步骤
- Backward Reasoning:从解决方案中推断出丢失的信息,掩码问题关键信息,要求根据解题步骤推断掩码信息。
实验
使用了CogMath框架后,相比原来都有下降,说明高估了模型的数学能力。
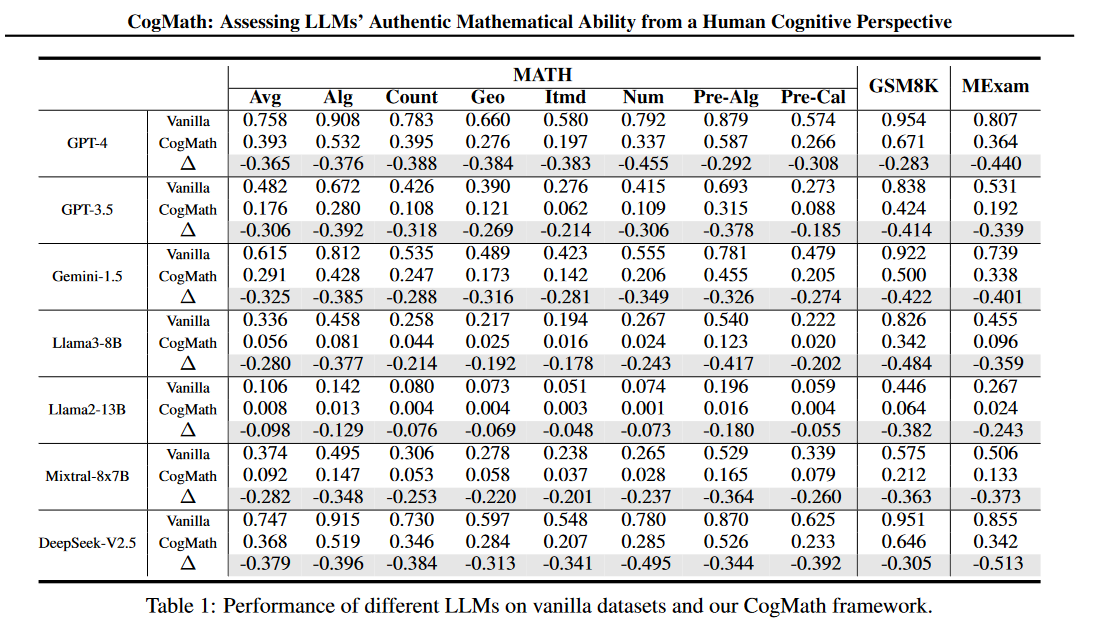
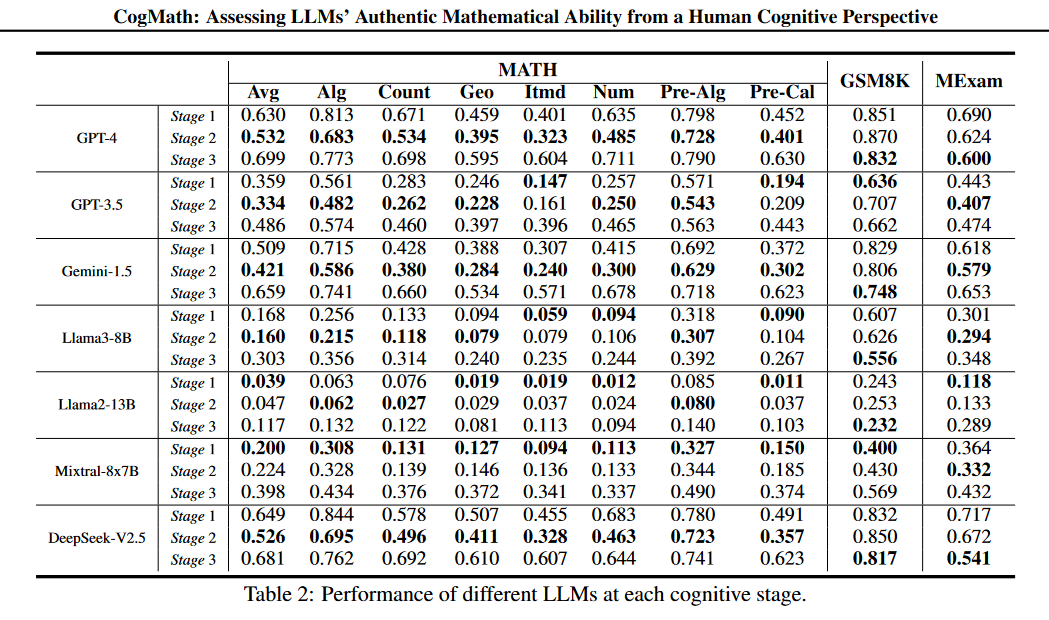
弱模型stage1的PR最低,强模型的的stage2能力尚待提高。而且模型普遍stage3分数偏低,说明他们不擅长反向推理,和之前研究表明检查答案的正确性是相关的。
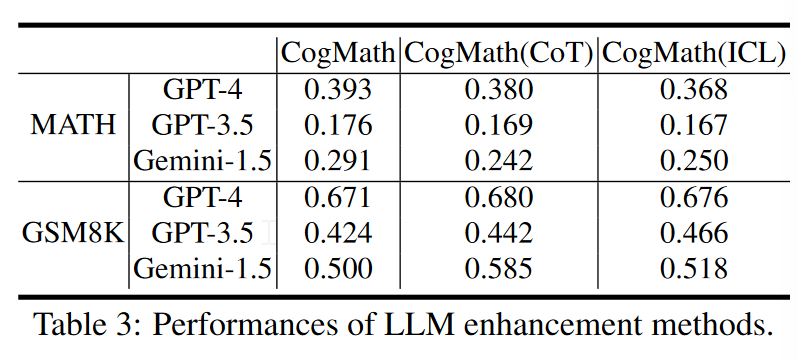
prompt技术不能从基础上增强模型
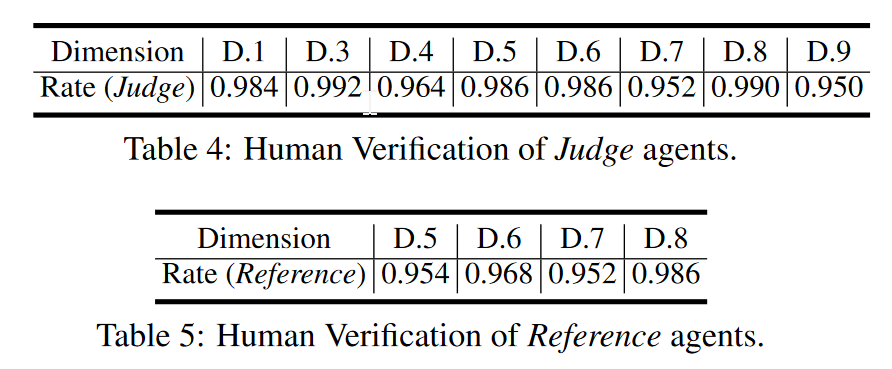
经过人类验证multi-agent能够实现他们各自的功能
自己的感悟
- 文章参考了心理学的人类推理的三个阶段,算是个学科交叉,搜了一下相关书籍有《思考,快与慢》
- 这个框架其实可以用在其他数据集上
- 出发点很有意思,就是看实验怎么论证
工作扩展
- 除了COT和ICL,后续其他技术ToT、RAG等也可以进行测试
This line appears after every note.
Notes mentioning this note
250701 250708 阅读
Prefix Tuning
[[ICML’23 BLIP-2 Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models]]