Icml'23 blip 2 bootstrapping language Image pre Training with frozen image encoders and large language models
文章理解
引言
之前工作的缺点:
- 在大型数据集上预训练,需要消耗大量算力
- 冻结单模态的预训练模型参数,没有见过图片的LLM如何进行多模态的对齐是十分具有挑战性的,现有的方法尝试利用图像到文本的生成损失,但这并不足弥补模式差距。
我们的解决方法:
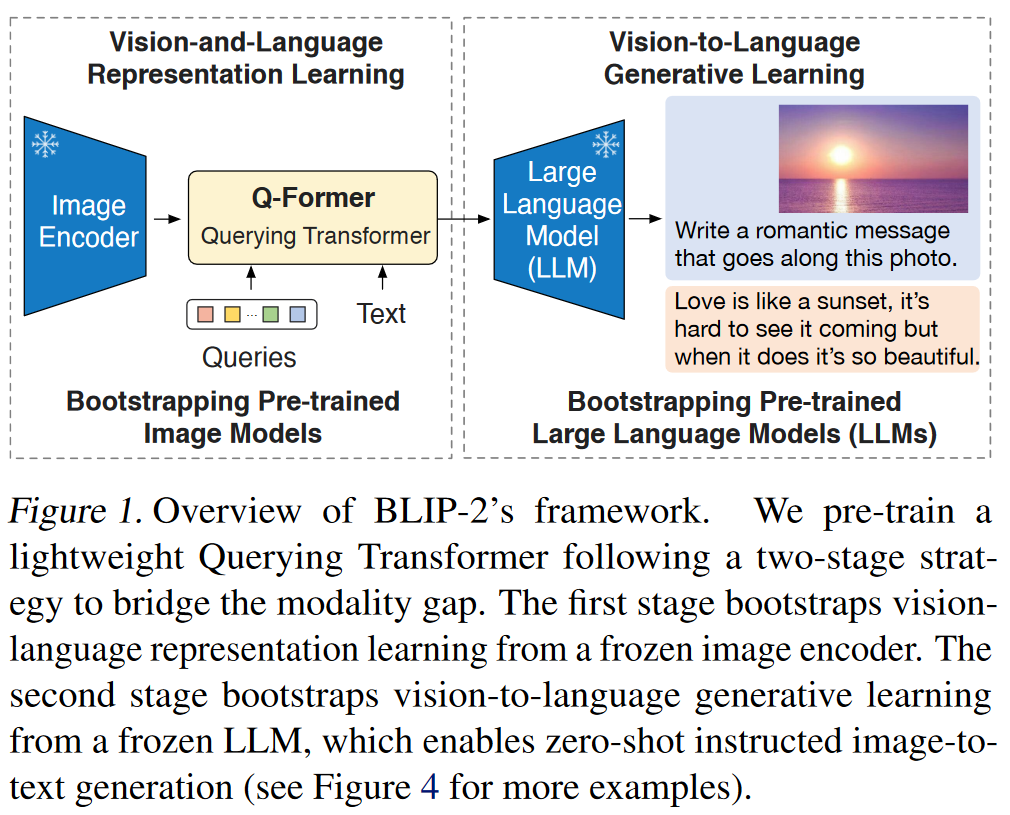
- 提出一个Querying Transformer(Q-Former),通过两阶段的训练策略得到合适参数,用来从冻结的图片编码器提取合适的视觉特征来喂给LLM从而输出预期的文本
论文优点:
- 提出了Q-former
- 利用LLMs,模型可以完成零样本的图片到文本的生成任务,并能遵循自然语言的指令,能完成视频知识推理和视频对话等任务。
- 计算效率更高,用更少的参数达到更好的效果
相关工作
- 端到端的视觉-语言预训练
-
模块化视觉的预训练
- 冻结图片编码器,比如冻结物体detector模块
- 针对视觉到文本的生成任务,冻结LLMs来利用里面的知识
- 关键点是如何对其视觉特征到文本空间。
- Frozen微调图片编码器,使其输出可以当做给LLM的soft prompts。
- Flamingo在LLM中插入新的交叉注意力层来注入视觉特征,用大规模数据集重新训练
- 两种方法都使用language model loss
Q-Former的设计方式
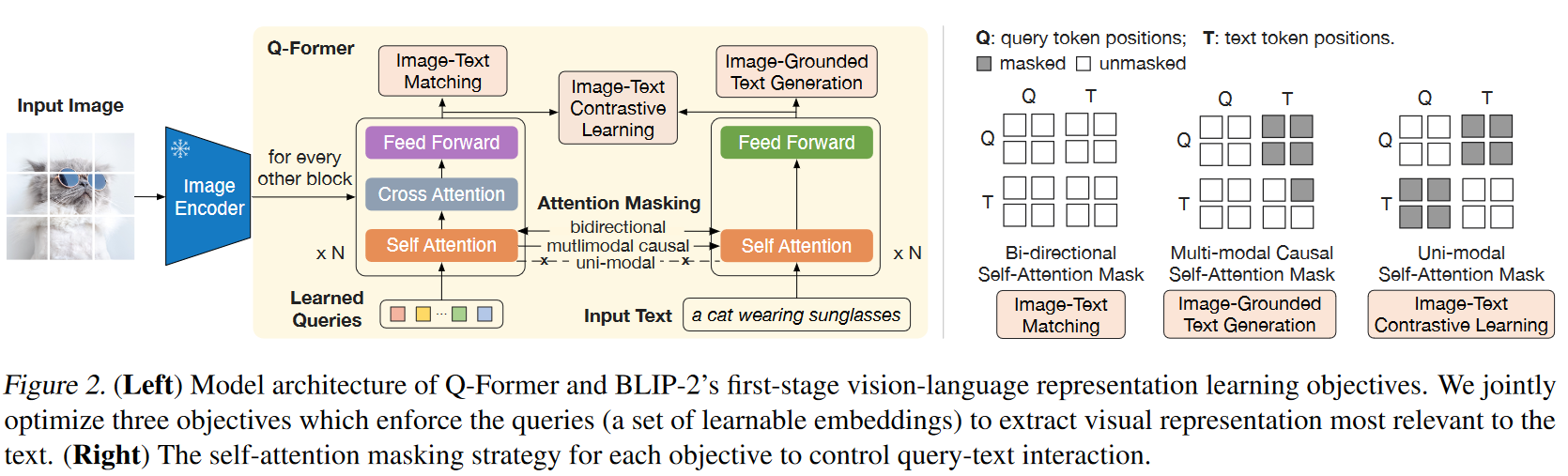
Q-Former的左边是一个用来和冻结的视觉编码器交互的一个图像transformer,右边是一个文本transformer,既可以用作文本编码器也可以用作文本解码器。图像transformer还要额外接受一组查询,这些查询可以看做是可训练的参数,是抽象的。Text transformer接受文本输入。这两个transformer共享self-attention的参数,根据不同的预训练任务使用特定的注意力编码,用于控制查询和Text token的交互。
- 图片文本匹配损失:双向自注意力掩码,查询和文本相互能看到所有信息,用于判断图像和文本是否匹配
- 基于图片的文本生成损失:多模态因果自注意力掩码。一个文本标记只能看到他之前的文本标记而没法看到之后的。同时Q到T灰色,说明在生成文本的过程中,image transformer不允许看到生成的文本,(从而强迫image transformer提取出和text有关的信息)。说明这个任务是纯粹的提供图像上下文,然后文本解码器再利用图像和文本上下文生成下一个词。
- 图片文本的对比学习损失:单模态自注意力掩码。查询不能得到文本token,文本token也无法得到查询信息,只允许单模态独立编码,确保学习到的表示在不直接依赖对方的情况下也能捕获各自模态的独立语义。
实验
…
自己的感悟
- 这个创新点主要是为了解决多模态的对齐问题,同时使用冻结的预训练模型来减少计算消耗。复用了BLIP中的三个训练目标策略,难点在于怎么想出对应的掩码策略,同时Q-former结构的可行性的实验。
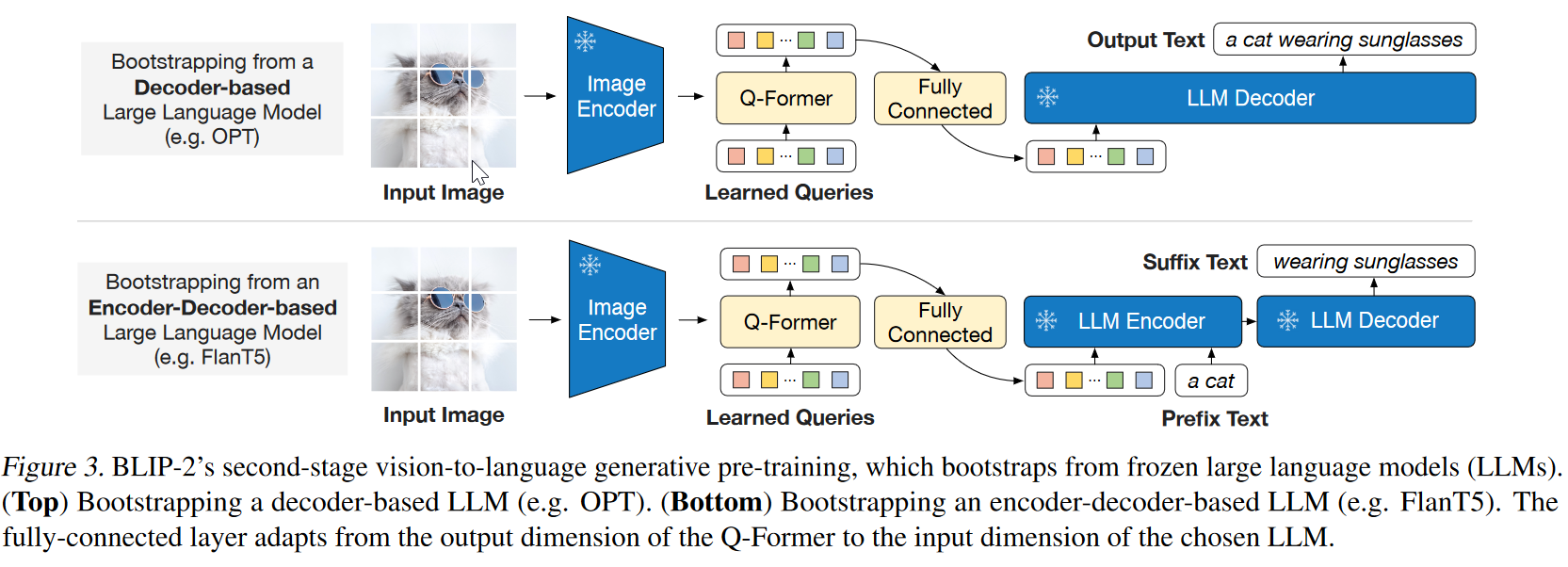
- Q-former有不少输入输出,需要理解清楚各自的用途。
工作扩展
- 能不能先不做多模态的,尝试只做文本的Q-former;目的不是多模态对齐,而是在单模态利用frozen的结构引入额外知识。
This line appears after every note.
Notes mentioning this note
250701 250708 阅读
Prefix Tuning
[[ICML’23 BLIP-2 Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models]]