⭐⭐⭐⭐⭐icml'22 blip bootstrapping language Image pre Training for unified vision Language understanding and generation
阅读时间:24.1.18 作者:Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi
1.引言
解决的问题:
- 大部分VLP只能做理解任务(例如图像文本检索)(编码器结构)或者生成任务(如图像字幕生成)(编解码结构)中的一种。
- 网络收集的训练数据集有噪音。
模型的两个贡献:
- 编解码器的混合:在image-text contrastive learning, image-text matching, and image- conditioned language modeling三个目标上联合训练
- 字幕生成器和过滤:净化数据集。
“bootstrapping” 通常指的是使用自生成的数据来改善模型的学习过程。
2.方法
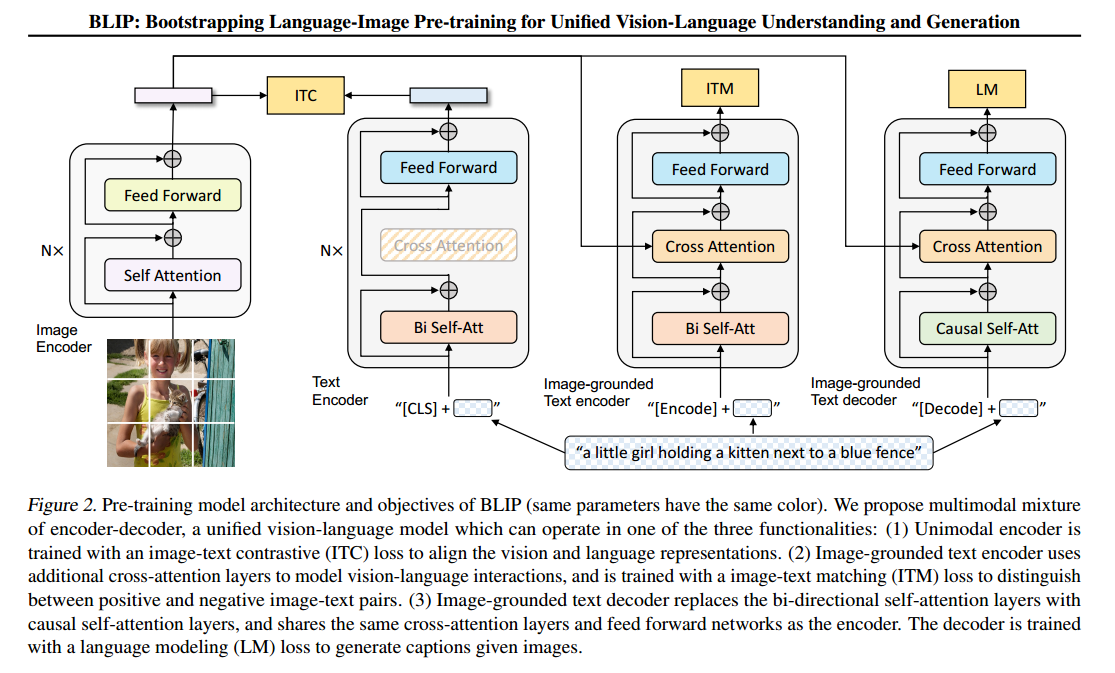
基本结构
- Self-Attention:它允许输入序列的每个元素都与序列中的其他元素进行直接的比较和交互。”Bi Self-Att” 表示双向自注意力,它可以同时考虑序列中前面和后面的信息,这通常用于编码器部分。
- Causal self-attention:单向自注意力,限制了模型只能注意到当前位置之前的信息。
- Cross-Attention (交叉注意力):允许模型将一种类型的表示(例如文本)与另一种类型的表示(例如图像)进行对比,这对于联合理解两种模态非常重要。交叉注意力使得文本编码器能够专注于与当前处理的文本片段最相关的图像部分。
- Feed forward网络:是一种典型的神经网络层,其中每个单元都与前一层的所有单元连接,但不与同一层的其他单元连接。用于在注意力机制处理后进一步变换特征表示。
模块
- Text encoder:与 Bert相同 ,和图像编码器的输出共同计算ITC(contrastive loss)
- Image-grounded text encoder:通过在文本编码器的每个transformer 块的自注意(SA)层和的前馈网络(FFN)之间插入一个额外的交叉注意(CA)层来注入视觉信息。特定于任务的[Encode]标记被附加到文本,并且[Encode]的输出嵌入被用作图像-文本对的多模式表示。用ITM(image-text matching loss)来训练,旨在学习图像-文本多模式表示。
- Image-grounded text decoder:用因果自注意代替双向自注意,计算LM(language model)loss,用来为给定图像生成字幕,使模型具有将视觉信息转换为连贯字幕的泛化能力。与encoder共享除SA层以外的参数。
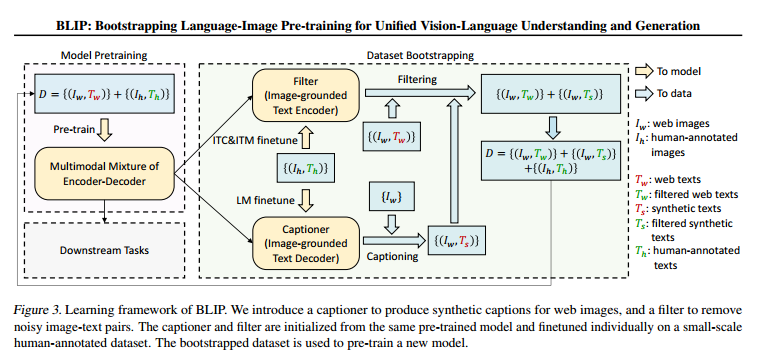 数据增强部分:合成文本+过滤文本
【?】:captioner本身也要学习图文的分布,才能输出匹配的文本。这和使用Stable Diffusion学习图文分布,再输出匹配文本的图片,重新进行训练有什么区别。
数据增强部分:合成文本+过滤文本
【?】:captioner本身也要学习图文的分布,才能输出匹配的文本。这和使用Stable Diffusion学习图文分布,再输出匹配文本的图片,重新进行训练有什么区别。
3.实验
-
消融实验,观察captioner和filter的作用
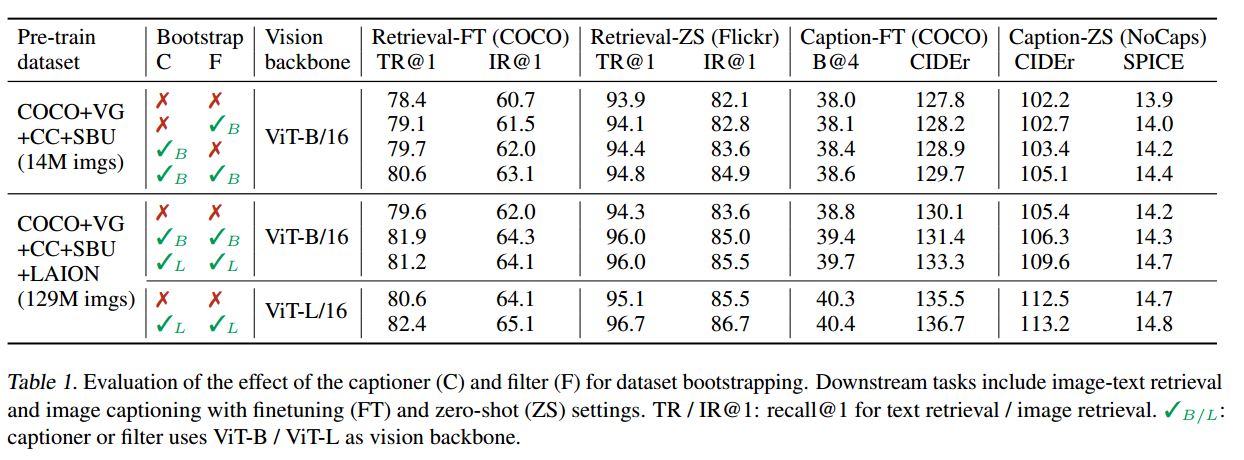
-
共享解码器和编码器的部分参数能有效减少训练量
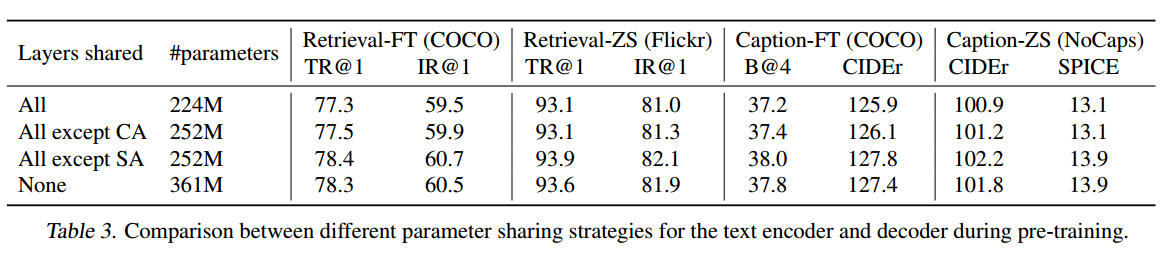
-
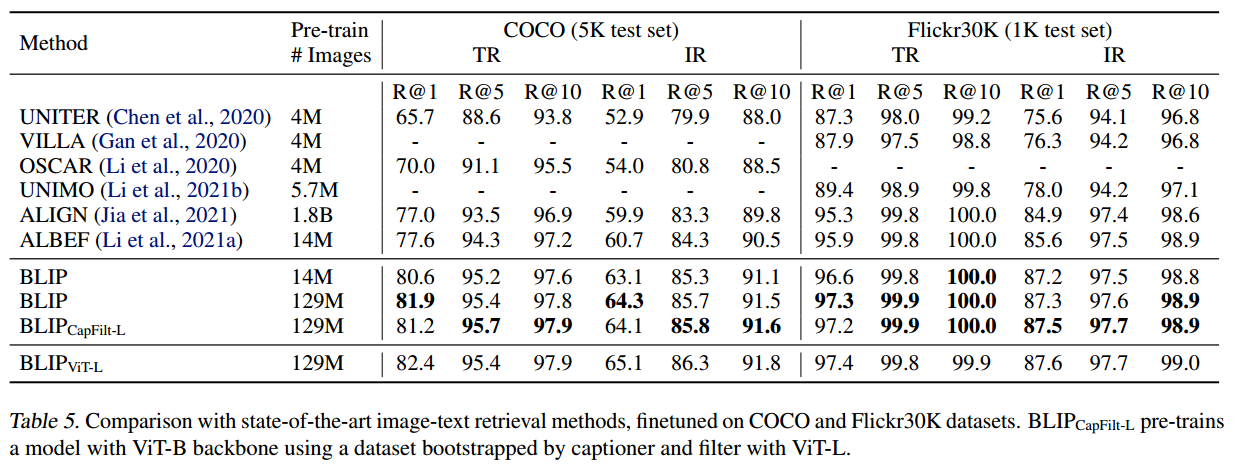
在COCO和Flickr30K数据集上评估了图像到文本检索(TR)和文本到图像检索(IR)的结果,与之前最先进的模型做比较。为了加速推理,先按相似度选k个候选人,再使用ITM重新排序得出最终结果
-
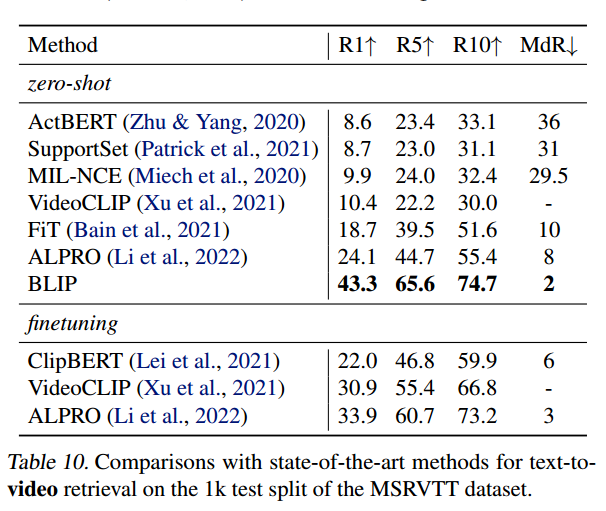
在缺乏时序信息的情况下,通过对视频的帧进行采样,完成文本-视频任务。可以看到BLIP有较好的zero-shot能力,若替换图片ViT为处理视频特征的模型,效果还能进一步提升。
总结
组合多个模块,实现多个任务。同时加入类似数据增强功能,通过净化caption,提高学习效果。前一点算是工程整合,不怎么具有创新性;后一点LaCLIP和他的工作是一样的,证明了数据的重要性。 但是能想到多个目标联合训练,将文本匹配对进一步和字幕生成结合检测结合来设计,增加参数量从而提高性能,这点很有新意。
This line appears after every note.
Notes mentioning this note
Paper Reading
0. Solid Ideas
Yoshua Bengio重新思考ML的投稿
1.Quantum Computing
[[TKDE’16_Relevance Feedback Algorithms Inspired By Quantum Detection]]