⭐⭐⭐⭐eccv'22 slip:self Supervision meets language Image pre Training
阅读时间: 24.1.17 作者: Norman Mu, Alexander Kirillov, David Wagner & Saining Xie
1.引言
三个测试任务:零样本迁移,线性分类,端到端微调。
2.方法
CLIP + SimCLR:在训练时同时计算CLIP的损失和SSL(Self-Supervised Learning)的损失,进行标量相加,作为训练损失。
- CLIP目标:在CLIP(Contrastive Language-Image Pre-training)目标中,模型将图像嵌入和字幕嵌入投影到一个512维空间中。这是通过分别学习的线性投影来实现的。CLIP目标的核心是通过这些投影将图像和相关文字描述对齐,即使图像嵌入和文字嵌入在一个共同的空间内尽可能相近。
- 自监督学习分支:在自监督学习分支中,模型使用一个3层的多层感知器(MLP)投影头,它有4096维的隐藏层,将图像嵌入转换到一个256维的输出空间。这个自监督任务通常涉及到图像的一些变换或扰动,模型需要预测这些变换,从而学习到图像的内在特征。
- 组合两个目标:将CLIP目标和自监督学习目标结合在一起,通常是通过将两者的损失函数加权和作为整体的损失函数。这意味着模型在训练过程中会同时尝试优化两个目标:一方面,它会尝试更好地对齐图像和文字嵌入(CLIP目标),另一方面,它还会努力学习从图像嵌入预测图像变换的能力(SSL目标),增强对图像特征的理解。
3.实验
- 用两个不同的自监督框架在不同数据集上训练ViT-B/16,在ImageNet这种没有被筛选过的数据集上训练,更有可能包含不平衡的类别分布、更多的噪声和不相关的信息,模型的效果更好。
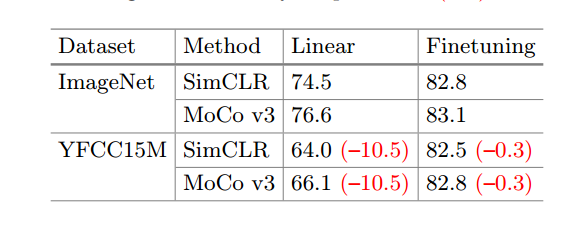
- 在ImageNet上的测试
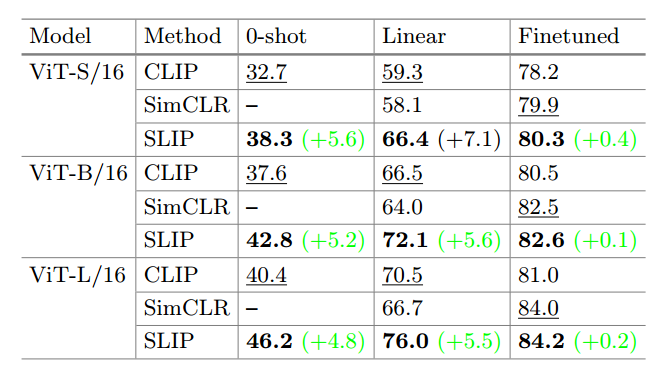
- 在不同的ViT模型上进行测试,在更大的模型和更长的训练时间上都能得到很好的扩展
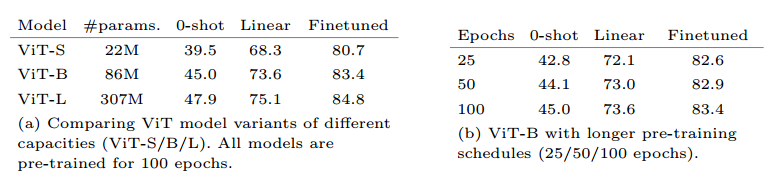
- 在zero shot transfer上测试了许多数据集,显示在大多数数据集桑德表现都比CLIP好,最后取了所有分数的平均。

- 不同的自监督框架的表现,SimCLR最好。
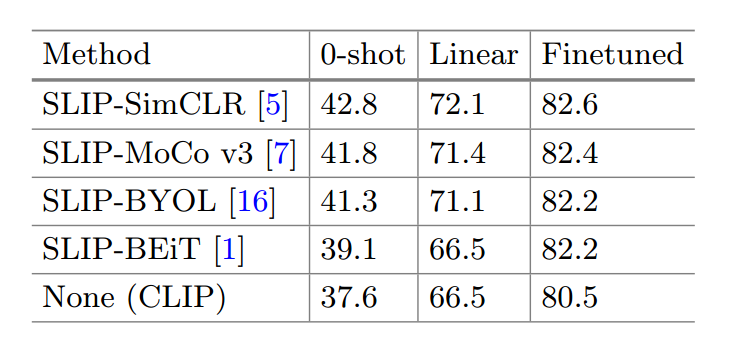
4.进一步的讨论
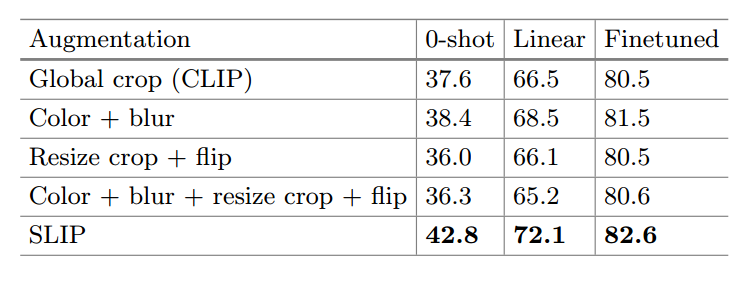
- SLIP不是简单的数据增强+CLIP
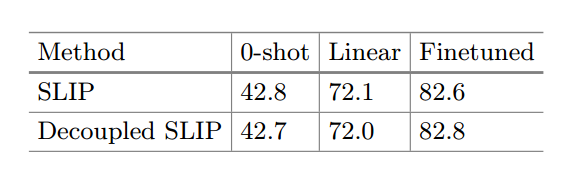
- 在训练过程中,从这两个数据集(用于语言-图像监督和用于自监督的数据集)中独立采样图像。这种做法有效地将语言-图像监督信号和自监督信号分开。结果发现,两个模型性能相同。说明在自监督学习和语言监督完全不同的情况下不影响模型表现。
收获
- 平均嵌入:提示模版+文字输入的每个类的平均作为最终的text feature。
- 缺点:SSL用来抓取图片特征,但是在zero-shot的情况下怀疑他在新数据集并没有好的泛化能力。
This line appears after every note.
Notes mentioning this note
Paper Reading
0. Solid Ideas
Yoshua Bengio重新思考ML的投稿
1.Quantum Computing
[[TKDE’16_Relevance Feedback Algorithms Inspired By Quantum Detection]]