Cikm'24 infinitymath a scalable instruction tuning dataset in programmatic mathematical reasoning
作者:Bo-Wen Zhang∗ Yan Yan∗ Lin Li Guang Liu 机构:北京人工智能研究院
文章理解
引言
之前工作的缺点:
- CoT和PoT通过引导模型展开推理步骤或者整合可执行的编程语句增强推理能力,允许编程解决复杂计算。于是合成指令微调数据集。但是高质量的问题是有限的,同时合成需要大量的计算成本。
- 在合成过程中,较小的数值变化导致推理步骤出错。比如惩罚变除法、编程时的参数含义改变 解决方法:
- 先根据问题生成一个标准的模版,通过创造问题的数值变体,运用相同的推理逻辑,来组成数据集 论文贡献:
- 创造一个大规模的指令微调数据集,用于编程数学推理
- 针对推理的逻辑不一致问题,修改问题中的数值来增强GSM8K和MATH数据集
相关工作
- CoT需要模型生成和计算数学表达,但是面对(LLM不擅长饿)多项式方程或者微积分会变效率低下
- PoT把计算步骤给额外的python解释程序
方法论
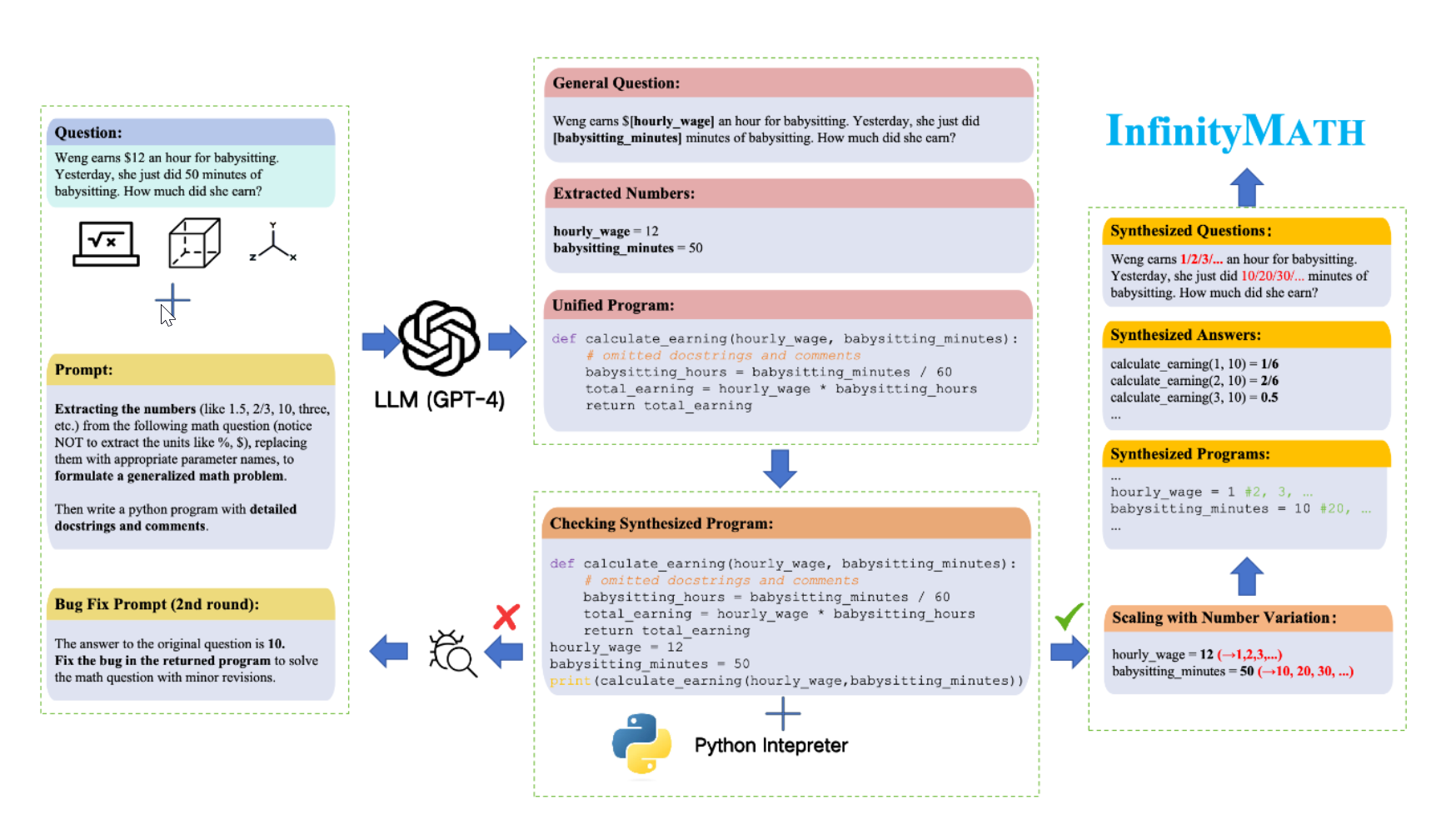 首先根据问题生成通用的编程解题模版,之后再用prompt进行验证,看是否有bug。如果没问题的话就根据这个“正确的”模版通过修改题目数据生成多个变体。在多个indomain 和 out of domain 上进行这个操作。
首先根据问题生成通用的编程解题模版,之后再用prompt进行验证,看是否有bug。如果没问题的话就根据这个“正确的”模版通过修改题目数据生成多个变体。在多个indomain 和 out of domain 上进行这个操作。
实验
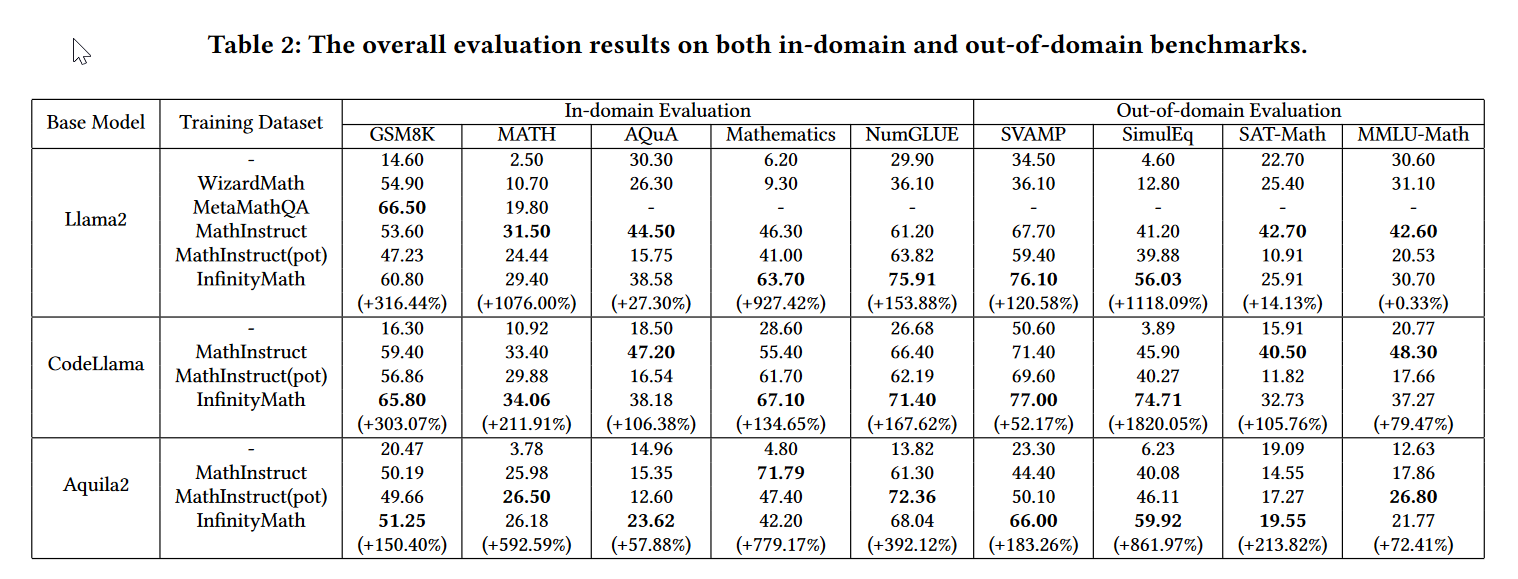
微调了部分base model 表现不错。
自己的感悟
- 感觉像小组作业,是一个很简单的扩展数据集的思路验证。
工作扩展
This line appears after every note.
Notes mentioning this note
250709 250716 阅读
Math Reasoning
[[ICML’25 Forest-of-Thought Scaling Test-Time Compute for Enhancing LLM Reasoning]]