⭐⭐⭐⭐⭐arxiv'2506 thought anchors which llm reasoning steps matter
作者:Paul C. Bogdan†,∗ Uzay Macar†,∗ Neel Nanda‡ Arthur Conmy‡
机构: Duke University Aiphabet
文章理解
引言
之前工作的缺点:
- 推理追踪缺乏可解释性的方法
- 传统的可解释性专注于简单的前向传递,理解激活,每个层如何处理,最后转化为输出。这种框架对于自回归推理模型太过细致了。一次只分析一个词元如何生成的微观分析方法,不适用于理解链式思维(Chain-of-Thought)因为他们需要将输出作为输入继续处理,太微观。相对地,句子比较微观,且与LLM推理步骤相吻合。
- 推理可能遵循一个结构,句子可以引入和导致更高级的计算目标,但对于这种结构的映射还不清楚。
思维锚thought anchors的定义:critical reasoning steps that guide the rest of the reasoning trace. 解决方法:有三种方式证明这个思维锚是存在的
- 黑盒方法:测量一个句子对最终答案和未来句子的反事实影响,通过重复采样,我们可以区分出计划句子,用于让模型开展数值计算。
- 白盒方法:receiver的注意力头会把注意放在特定的boradcasting 句子上。我们开发了一种系统性的方法识别接收头。
- 方法三:推理轨迹中特定句子对之间的因果关系。在之后的token生成中,对某个句子进行掩码,测量抑制的影响。这个能反应每个句子之间的因果关系。
- 工作能够在句子层面上分析推理路径,也能够更加精准地定位推理失败的原因,识别不可靠信息的来源,增强推理稳定性。
设置
句子分类:
- Problem Setup: Parsing or rephrasing the problem
- Plan Generation: Stating or deciding on a plan of action, meta-reasoning
- Fact Retrieval: Recalling facts, formulas, problem details without computation
- Active Computation: Algebra, calculations, or other manipulations toward the answer
- ==Uncertainty Management: Expressing confusion, re-evaluating, including backtracking ==
- Result Consolidation: Aggregating intermediate results, summarizing, or preparing
- Self Checking: Verifying previous steps, checking calculations, and re-confirmations
- Final Answer Emission: Explicitly stating the final answer
数据集选择
- 10个问题,在1000个问题上生成10次回答,模型在25%-75%的次数上能解决问题
黑盒方法
想法:包括或排除一个句子如何影响后续步骤和模型的最终输出?
图A代表的是中断推理让模型直接给出回答。在关键句子前的Forced importantce应该都不高,所以对于那些早起的步骤没法准确地测量
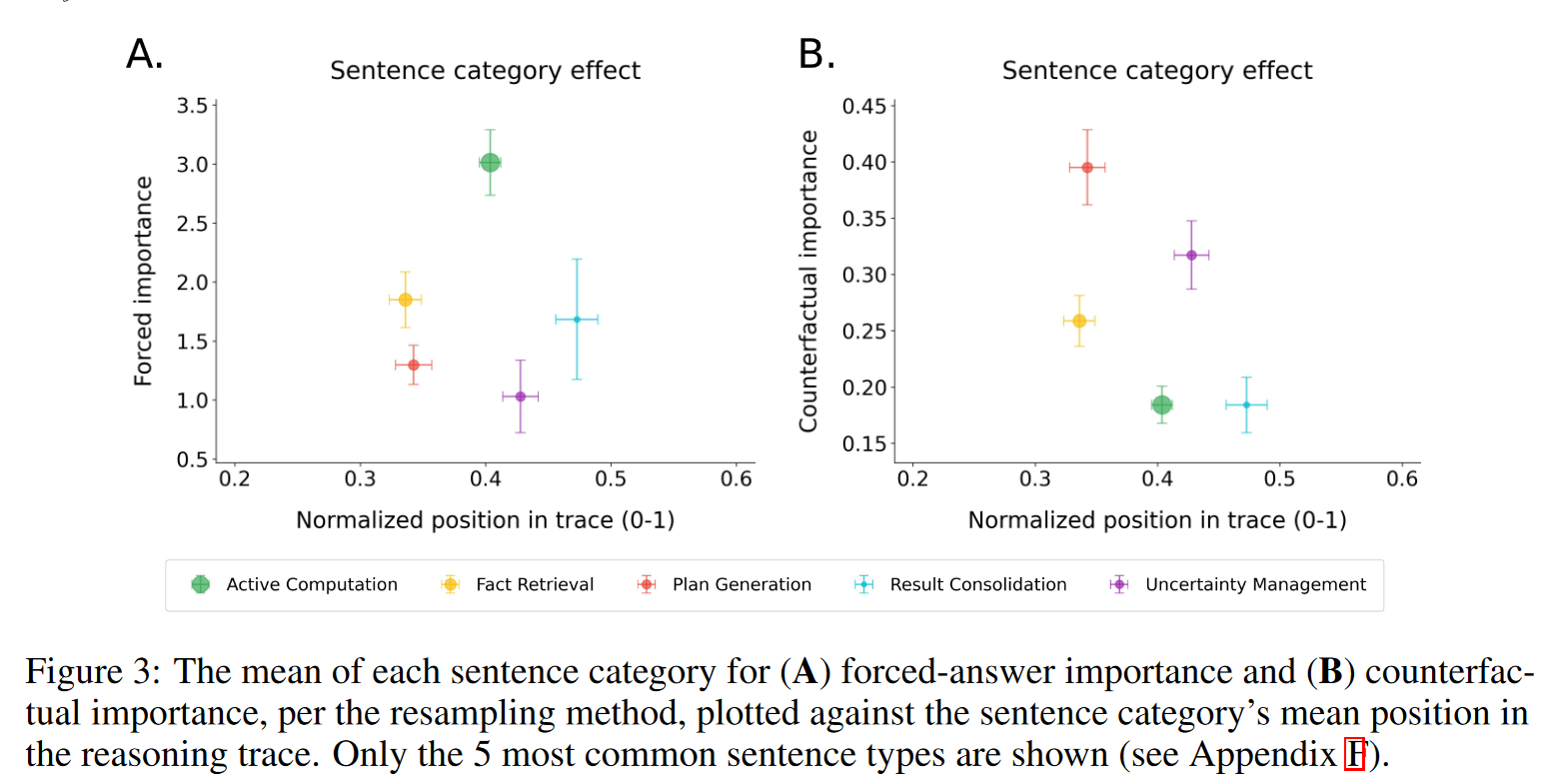
counterfactual importance
- 抽样:生成两组,每组100次的完整推理。第一组不包含句子S,即S的前一句,第二组包含句子S
- 分布比较:计算两种条件下最终答案分布之间的“KL散度”,衡量句子对最终答案的改变有多大,称作resampling importance
- 语义过滤:第一组存在生成的下一个步骤很接近S需要提出,最后CI的计算是考虑下一个步骤与S语义不同的情况。
- 结果:像“计划生成”和“不确定性管理”(如回溯检查)这样的高层次句子,比具体的“主动计算”句子具有更高的反事实重要性,因为它们起到了组织和引导推理方向的关键作用 。
注意力融合
分析模型的注意力机制来识别出那些专门负责聚焦于特定重要句子的注意力头 。
- 对于一条推理链,他们将每个注意力头原始的“词元-词元 (token-token)”注意力矩阵,通过计算任意两个句子之间所有词元对的平均注意力权重,转换成一个“句子-句子”的注意力矩阵。
- 计算句子的“被关注度”:基于这个新的句子矩阵,他们计算每一列在对角线以下的均值。这衡量了每个句子从所有后续(downstream)句子那里接收到的平均注意力。为了专注于长距离的连接,他们只计算那些相隔至少四个句子的句子对。
- 用“峰度 (Kurtosis)”量化聚焦程度:上述步骤为每个注意力头都生成了一个注意力得分的分布(每个句子一个分值)。一个注意力头将注意力集中于少数特定句子的程度,可以通过其分值分布的“峰度”来量化。峰度值越高,说明该注意力头的注意力越集中,而不是分散的。
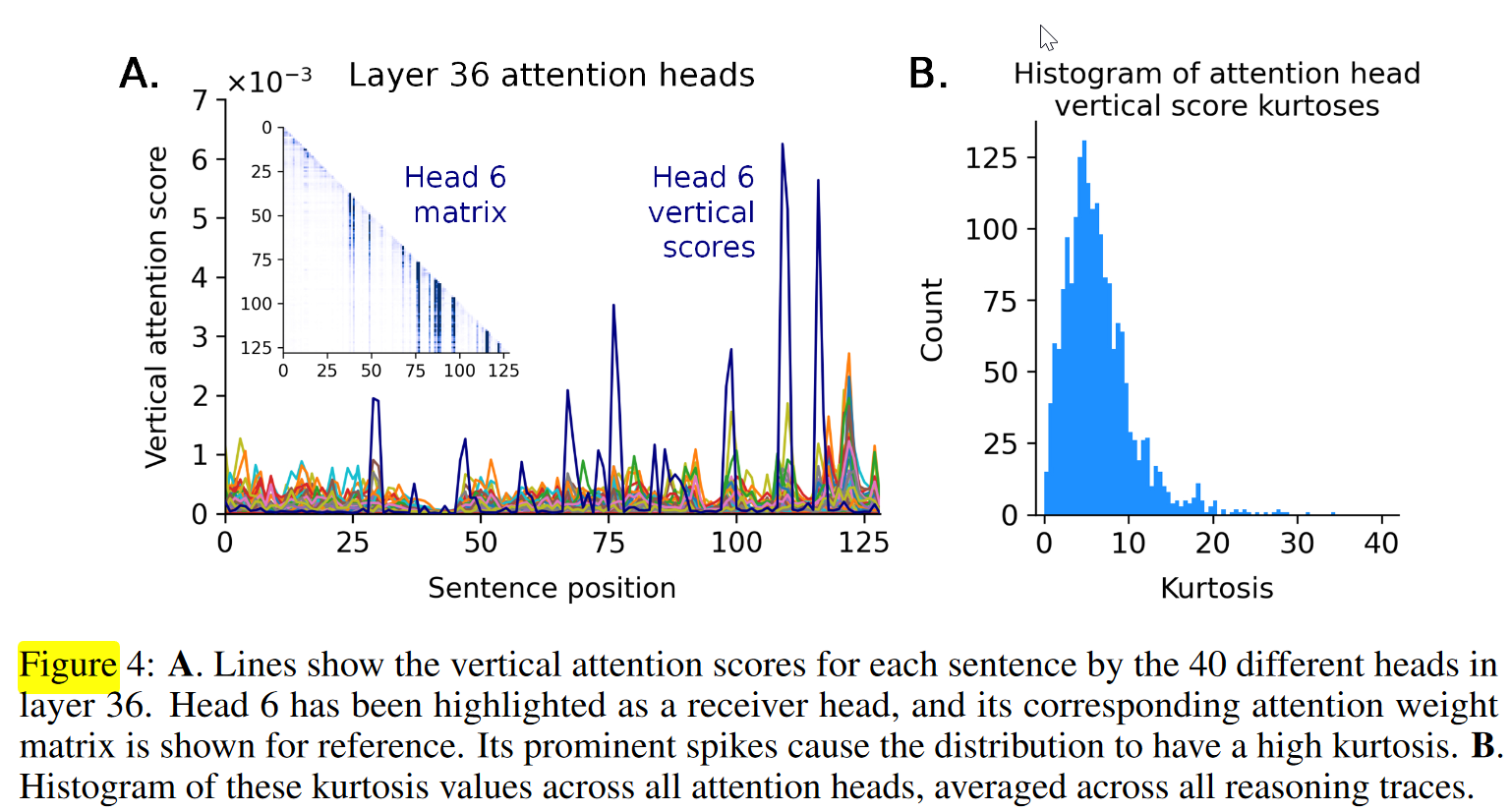
结论
- 不同的“接收者头”通常会将注意力引向相同的句子。所以推理链中确实存在一些内在的重要句子,而这些“接收者头”正是在识别它们。
- 对比推理模型(R1-Distill-Qwen-14B)和其基础模型(Qwen-14B),研究发现推理模型的“接收者头”能更大程度地将注意力集中到单个句子上。
- 移除(ablate)这些“接收者头”比随机移除其他自注意力头,对模型准确率的降低幅度更大。
-
“计划生成(Plan generation)”、“不确定性管理(uncertainty management)”和“自我检查(self checking)”这几类句子,稳定地从“接收者头”那里获得最多的注意力。而“主动计算(active computation)”类型的句子获得的注意力则最少。
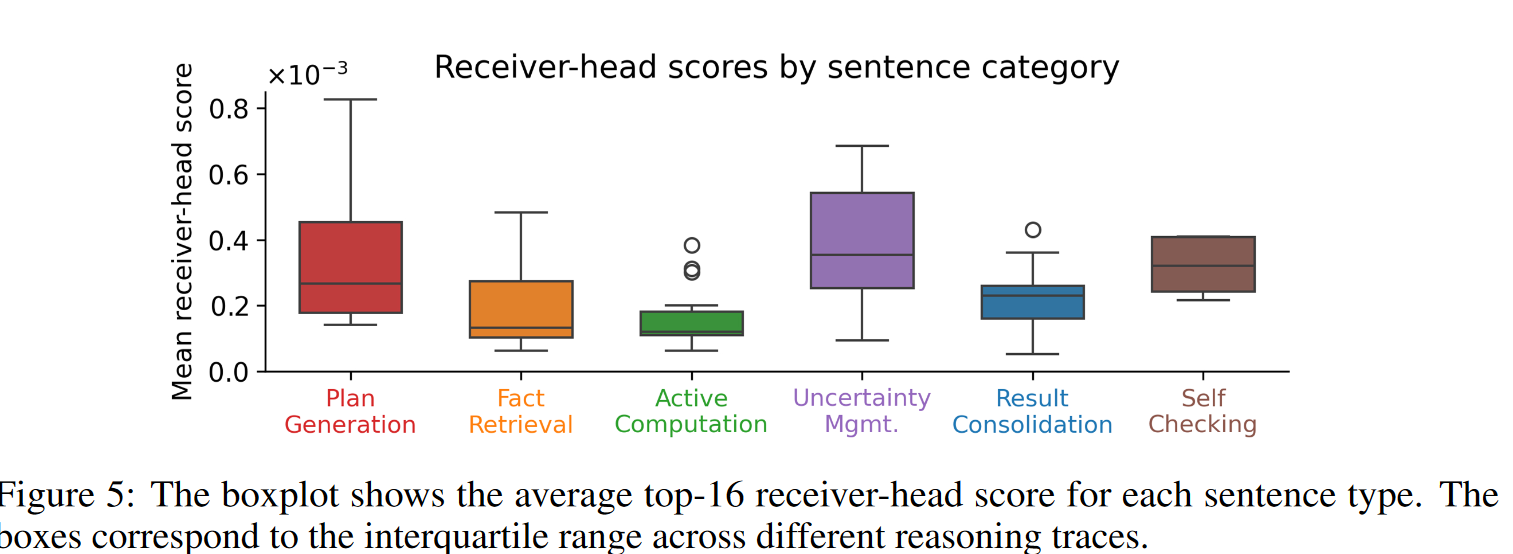
- 一个句子从“接收者头”获得的注意力越多,它通过重采样方法(resampling method)测得的对下游句子的因果影响也越大
注意抑制
分析注意力无法衡量因果关系,他们无法识别句子与未来句子的联系。
- 他们会完全抑制(在模型的所有层和所有注意力头中)流向某个特定句子的全部注意力,然后观察这个操作对未来句子的影响。
- 影响的大小被定义为“KL散度(KL divergence)”,即比较在有抑制和无抑制两种情况下,未来某个词元(token)的 logits(模型在输出前计算的原始概率分布)之间的差异。一个未来句子所受到的影响,是其构成词元所受影响的平均值。
具体例子
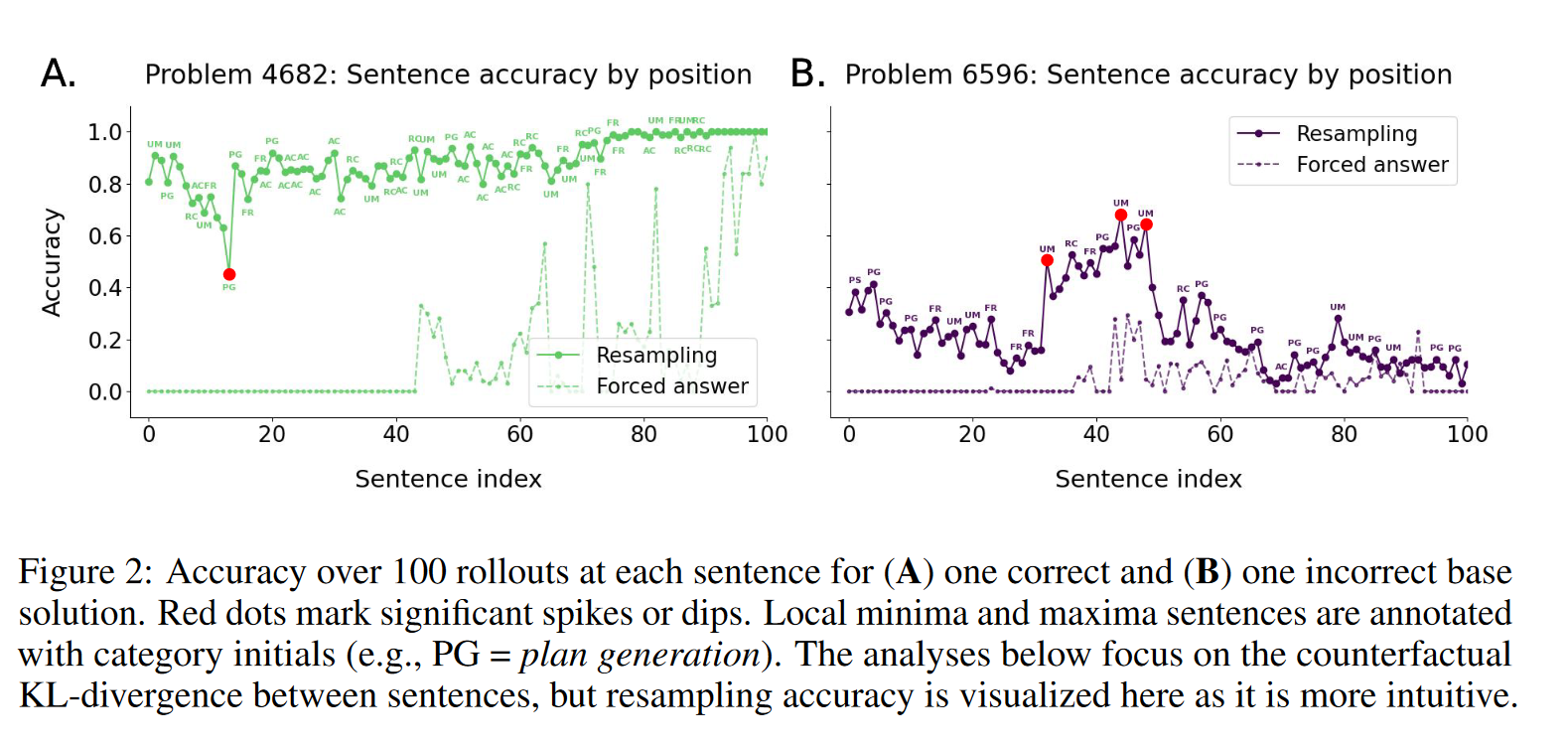
问题:“当十六进制数 66666₁₆ 写成二进制时,它有多少位数字(比特)?” 。
模型的推理路径:模型首先提出了一个简单但错误的思路:66666₁₆ 有5个数字,每个十六进制数字对应4个比特,因此答案是 5 * 4 = 20 比特 。然而,正确答案其实是19比特 。模型在其推理过程中,通过一个更复杂的计算路径(先转十进制再转二进制)发现了这个正确答案,并最终解决了最初思路与正确答案之间的矛盾 。
resampling
句子13(“或者,也许我可以计算 66666₁₆ 的十进制值,然后再找出这个数需要多少比特”)被识别为具有极高“反事实重要性”的句子 。正是这个句子让模型扭转了错误的推理轨迹,转向了通往正确答案的路径,使得预期准确率急剧上升。而forced answer就没法看出来
receiver heads
通过追踪高注意力的句子,可以将模型推理过程清晰分段
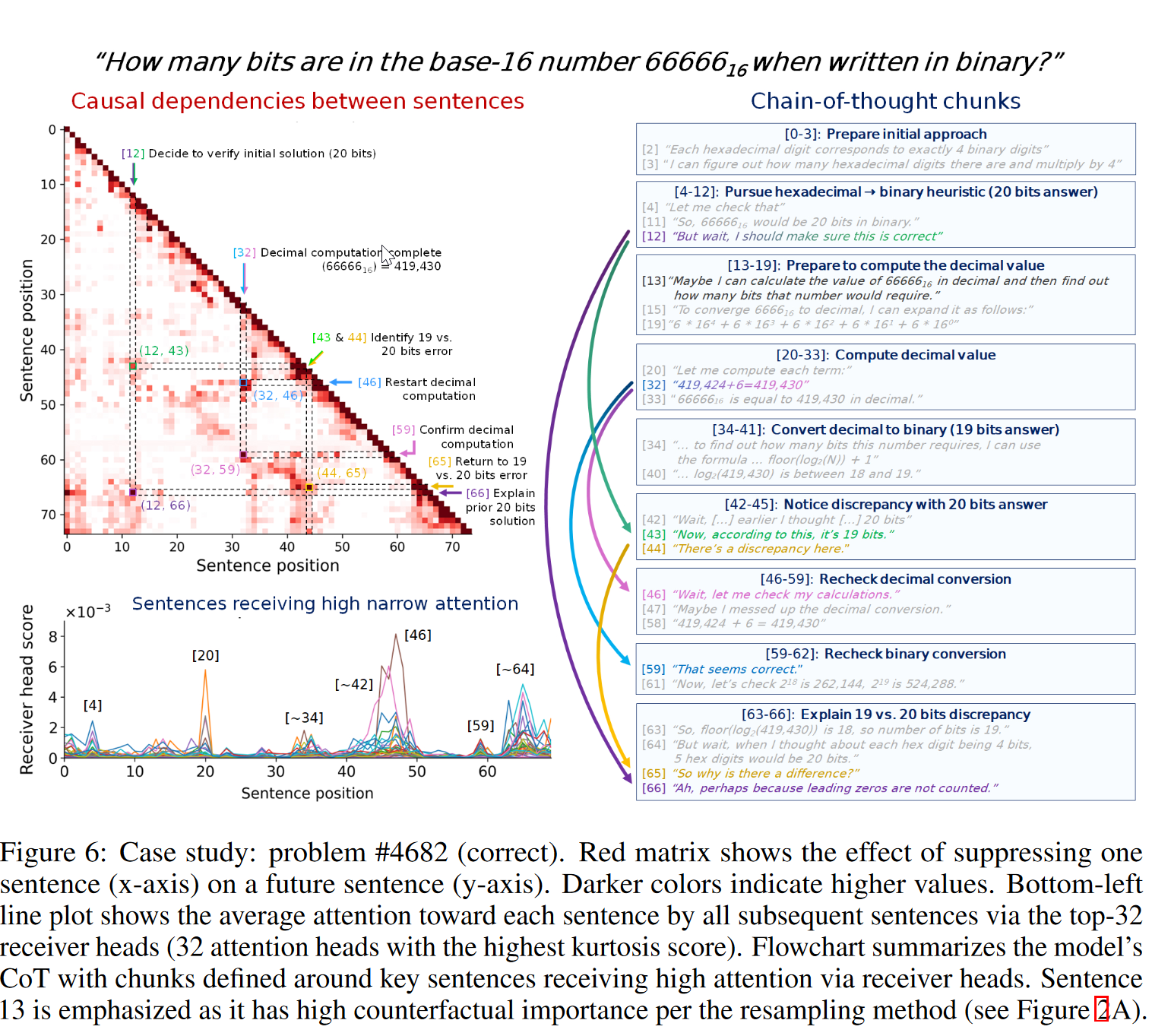
注意抑制
展示自我纠错的模式
- 最初决定重新检查的句子 (句12),直接导致了后来注意到矛盾的句子 (句43)
- 注意到矛盾 (句43) 又直接促使模型在后续回顾并解释这个矛盾 (句65) 。
- 决定验证十进制计算的句子 (句46),直接引用了早前完成十进制计算的句子
局限性
- 多重决定的问题:分析方法需要进一步完善,以处理下游句子可能由推理过程中的不同轨迹或多个独立的充分原因共同导致(overdetermined)的复杂情况。
- 未研究纠错机制:论文没有正式地研究模型进行“纠错”的作用。
- “接收者头”分析的混淆因素:“接收者头”分数的分析会受到句子在推理轨迹中所处位置的干扰(详见附录M)。
- “注意力抑制”方法的局限性:“注意力抑制”这项工作的局限性在于,它实际上要求模型去处理“分布外”(out-of-distribution)的信息,这可能不是模型正常运作的方式。
自己的感悟
- 针对模型可解释性做了方法讲解和可视化,我觉得可视化的内容非常令人信服,希望不是找的个例
- 三个方法都验证了同一个结论
- 对attention的操作要求对模型的结果还是有一定的认知。
工作扩展
- 可以用来分析我们的模型结构的工作是否有改善推理,比如引入了压缩后的信息后,resampling有什么变化。
This line appears after every note.