⭐⭐⭐arxiv'2506 scida scientific dynamic assessor of llms
作者:
机构:字节、北大
文章理解
引言
之前工作的缺点:
- 存在数据污染,由于评测基准的数据(如教科书、竞赛试题)很可能也被用于训练LLM,模型可能只是“记住”了特定问题的答案模式,而不是真正学会了推理,这导致了对其能力的系统性高估 。 解决方法:
- 提出了动态的、跨学科的科学问题基准
相关工作
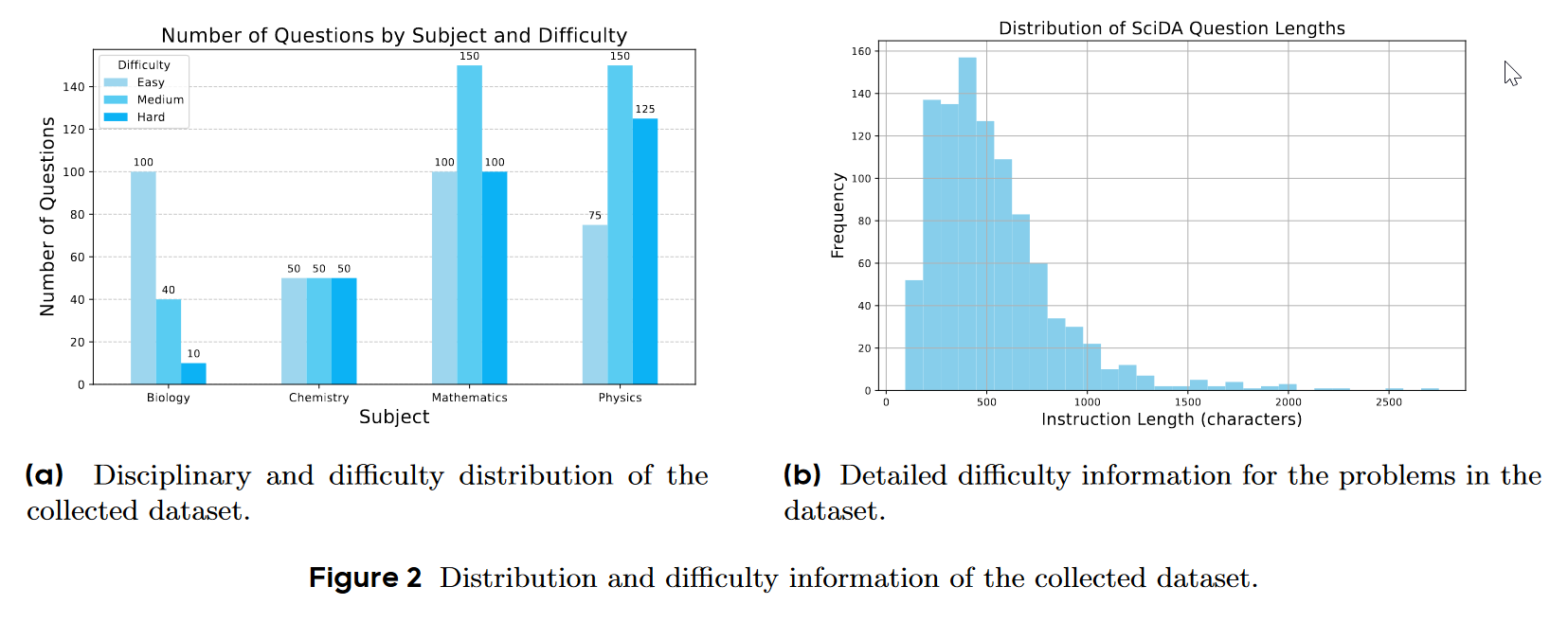
特点
- Dynamic Random Initialization:将问题中的关键参数变量化,每次评测从有效的值域上随机抽取,让模型无法依赖记忆回答
- 数据集来源:由竞赛获奖学生从国际奥赛、大学教科书以及私有题库中精心收集。筛选符合描述变量的问,然后通过编写python解决这些问题。
- SciDA涵盖了自然科学的四个核心领域,确保了评估的全面性 :
- 数学:微积分、代数、数论 。
- 物理:力学、光学、天体物理、电动力学、量子力学等 。
- 化学:物理化学、分析化学、无机化学、有机化学 。
- 生物:遗传学、生态学、分子生物学等 。
实验结论
- 随机化后表现下降10%-20%
-
具备慢思考如doubao–pro表现更好
- 在随机化后,数学和物理学科的准确率下降最为严重(降幅可达30%至70%),而化学和生物受影响相对较小 。因为数学和物理问题通常需要更长的推理链,涉及更多变量,并且存在一些经典的、容易被模型记住的数字模式 。
- 研究发现,在数学、物理等模型泛化能力较好的学科中,计算错误是主要的错误类型 。而在生物等训练语料相对稀缺的学科中,逻辑错误(如用错公式、推理过程有误)的比例几乎与计算错误相当,这表明模型的泛化能力不足 。一个学科中“逻辑错误”的比例越高,就越说明模型没有掌握该学科的通用解题规律,仅仅是机械地记忆了某些固定模式。
自己的感悟
工作扩展
This line appears after every note.
Notes mentioning this note
250709 250716 阅读
Math Reasoning
[[ICML’25 Forest-of-Thought Scaling Test-Time Compute for Enhancing LLM Reasoning]]