⭐⭐⭐⭐arxiv'2505 soft thinking unlocking the reasoning potential of llms in continuous concept space
作者:Zhen Zhang1∗ Xuehai He2∗ Weixiang Yan1 Ao Shen4 Chenyang Zhao3,5 Shuohang Wang6 Yelong Shen6 Xin Eric Wang1,2
机构:University of California,Purdue University,LMSYS Org, Microsoft
文章理解
引言
之前工作的缺点:
- CoT这种利用离散的预定义的token限制了LLM的表现和转换抽象概念。神经科学有证据表明人类大脑处理信息是在抽象概念的层级而非单词层级。
- CoT是单向且序列化的,采样token,致力于一个特定的分支,容易导致不正确或者次优的推理路径,消耗token。人类是可以思考多种可能来处理复杂问题。
- 解决方法:
- 免去训练的方法:产生soft 抽象的概念token在连续概念空间中来进行软推理。这个token由token embedding的概率加权混合产生。赋予每个输出令牌更细微和细粒度的语义,并在概念上可以处理多个路径。(因为“概念词元”保留了下一步所有可能词元的概率信息,它相当于封装了多条潜在推理路径的语义 。模型不是在一条路径上走到黑,而是在每一步都保留着一个包含多种可能性的“叠加态” 。)
- 形成all token embbeding的组合,模型可以抓住概念
- 因为每个concept tokens 并行地保持了概率分布,可以显式地探索多个推理路径。
- 提出cold stop机制,当过度自信时中断中间推理步骤
论文贡献:
- 实验提升2.48,同时相比CoT减少了最多22.4%的token使用量
相关工作
- CoT推理
-
continuous space reasoning 在连续空间推理(这里提到的论文都可以看,有利于理解hidden state的发展和使用)
- 表明可以从隐藏表示解码中间推理变量;对hidden statte进行干预,来操纵推理结果
- 小于7B模型,输入嵌入层和输出语言模型头是绑定的,需要在广泛训练对齐输入和输出的空间。而大于7B的模型,组件通常可以拆借,在不同空间中直接使用hidden state会导致表示不匹配,很难用大量训练来对齐。
方法论
Preliminary: Standard Chain-of-Thought Decoding
- 模型接收输入后,会先生成一系列中间推理步骤(即“思维链”) 。
- 在每一步,模型都会根据之前所有的内容(输入+已生成的推理),计算出词汇表中每个词元的概率,然后从中采样一个离散的词元作为下一步 。
- 当生成一个特殊的“思考结束”标志(如 </think>)后,推理阶段结束,模型开始生成最终答案 。 这个过程的特点是每一步都做出一个“硬决策”,只选择一条路径继续下去
Soft thinking
在任何一个中间推理步骤,模型生成的不再是一个单一的词元,而是词汇表上所有词元的完整概率分布 。这个概率向量本身,就被定义为“概念词元” (ct) ,从而避免过早做出hard decision
- 软思维只在中间推理阶段取代标准CoT,最终答案的生成方式仍然是标准的离散采样 。
- 在每一步推理中,模型生成一个概率分布,即“概念词元” 。
- 这个“概念词元”通过对所有词元嵌入进行加权求和,生成一个新的嵌入向量,并将其作为下一轮的输入 。
- 当“概念词元”中概率最高的词是“思考结束”标志时,推理停止 。
- 之后进入答案生成阶段,模型将上述全部内容(输入问题、Soft Thinking阶段生成的所有“概念词元”所代表的推理过程。)作为提示(Prompt),然后切换回标准的、离散的解码模式来逐个生成最终的答案词元 。
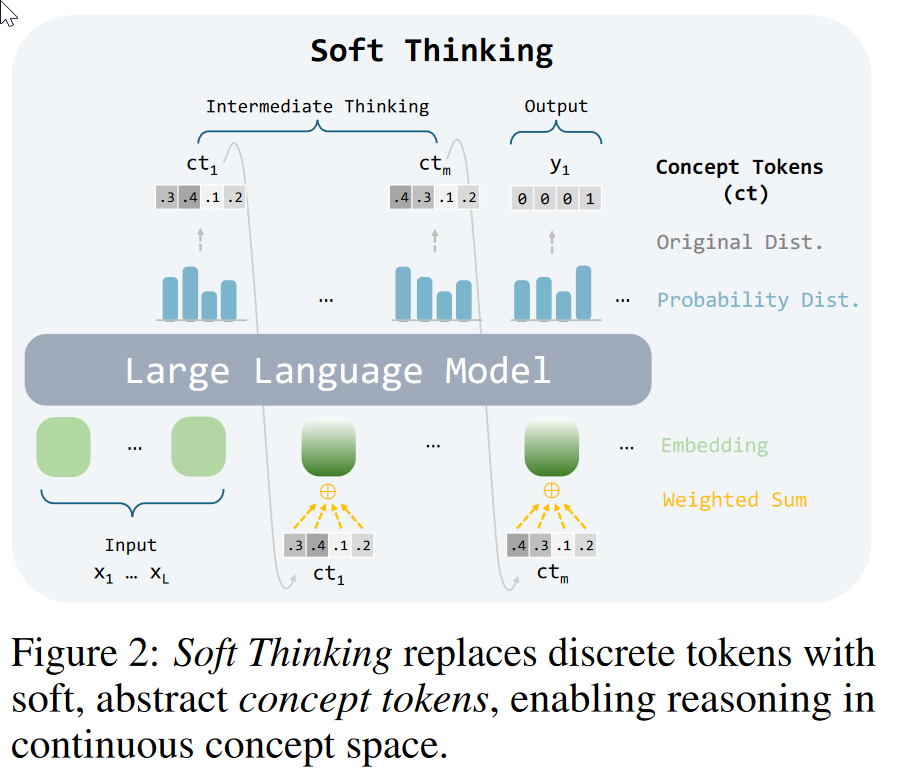
Cold Stop
由于模型在训练时从未见过“概念词元”这种连续的嵌入向量,直接在推理时使用会导致其处于“分布外”(Out-of-Distribution, OOD)状态,长时间运行可能导致模型崩溃(如无限重复)
- 在每一步计算“概念词元”的熵 (Entropy) 。低熵意味着模型对其预测非常自信 。
- 如果连续几步的熵都低于一个预设的阈值,系统就会认为模型已经足够自信,可以得出结论了 。此时,会自动插入一个“思考结束”标志,终止推理,开始生成答案 。
理论
要得到一个答案最精确的概率,理论上需要将所有可能的推理路径的概率全部相加,但这个计算量是指数级的,不现实 。
- 通过一系列线性近似来逼近这个“全路径加和”的结果 。
实验
数据集
- MATH:Math500 [31], AIME 2024 [32], GSM8K [33], and GPQA-Diamond
- Code:HumanEval [35], MBPPMBPP [36], and LiveCodeBench
模型
- QwQ-32B [13], DeepSeek-R1-Distill-Qwen-32B [38], and DeepSeek-R1-Distill-Llama-70B
对比:标准CoT和贪婪CoT
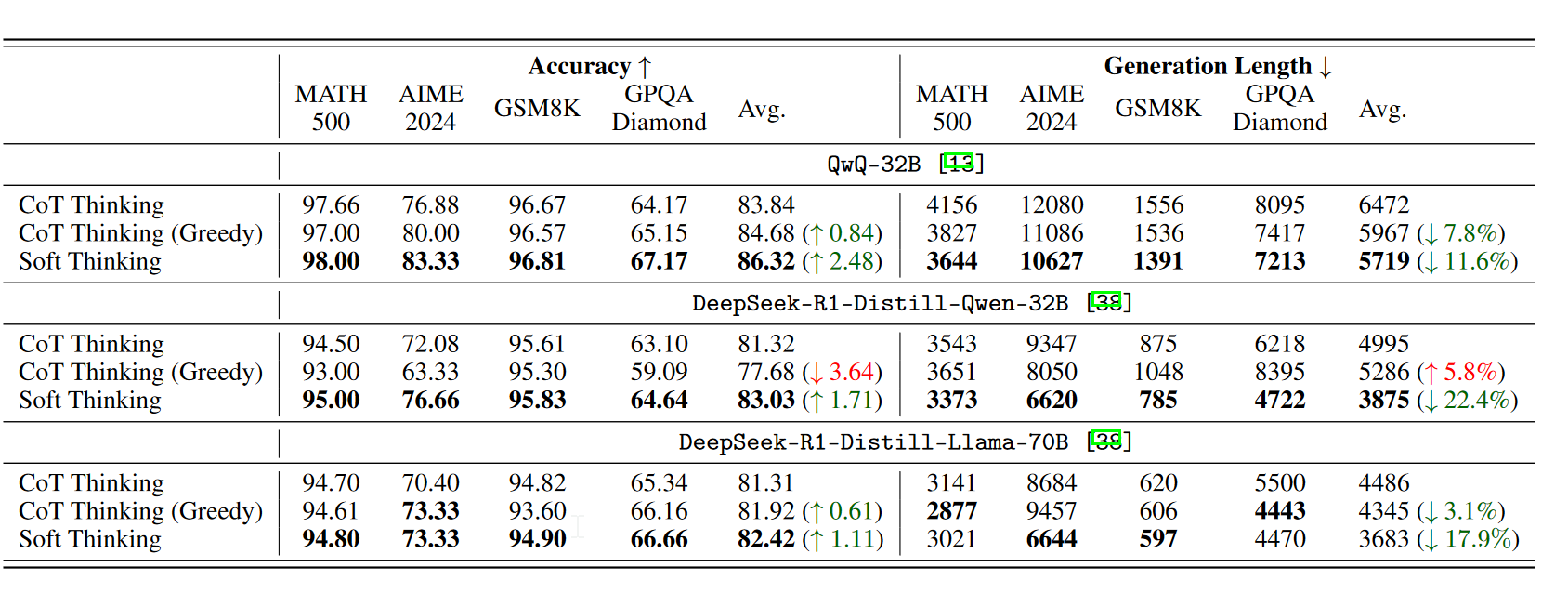
在数学数据集上的表现
在code数据集上的表现
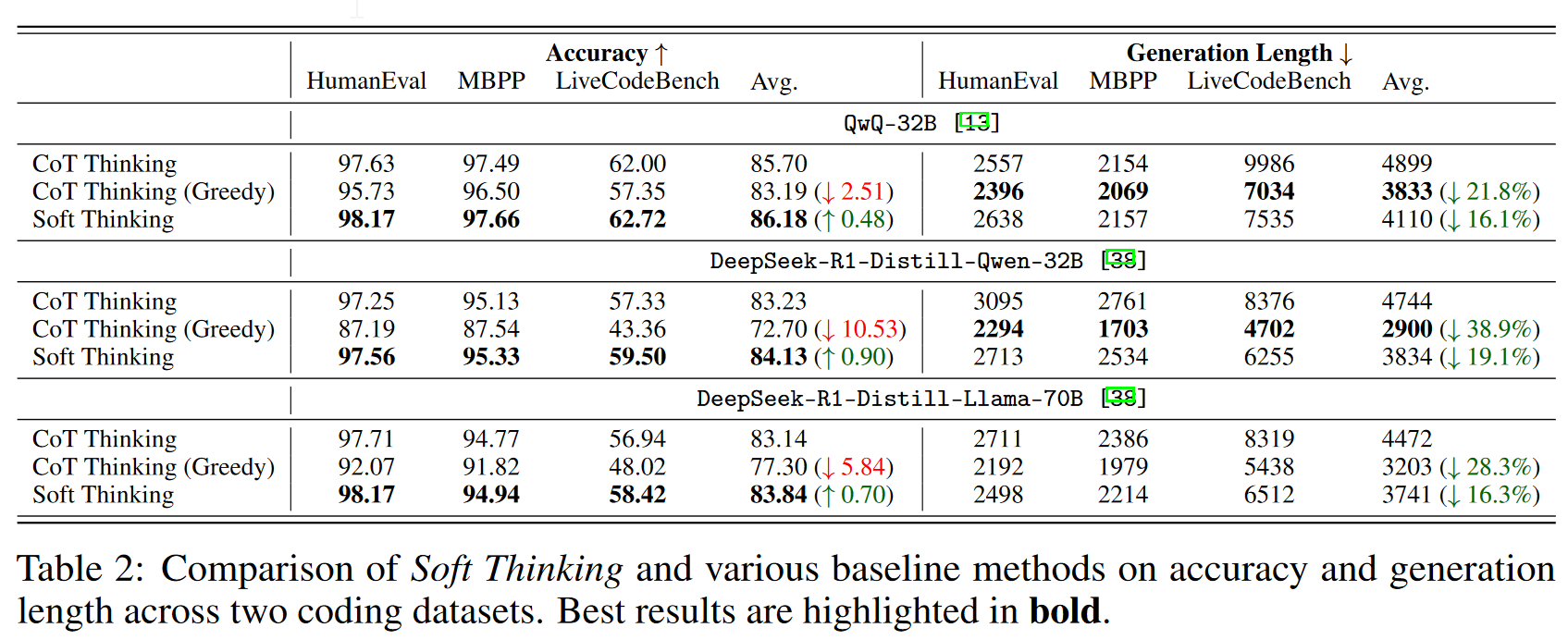 其中贪婪CoT生成长度显著下降,而精确率也随着下降
其中贪婪CoT生成长度显著下降,而精确率也随着下降
量化实验

soft thinking更加精简
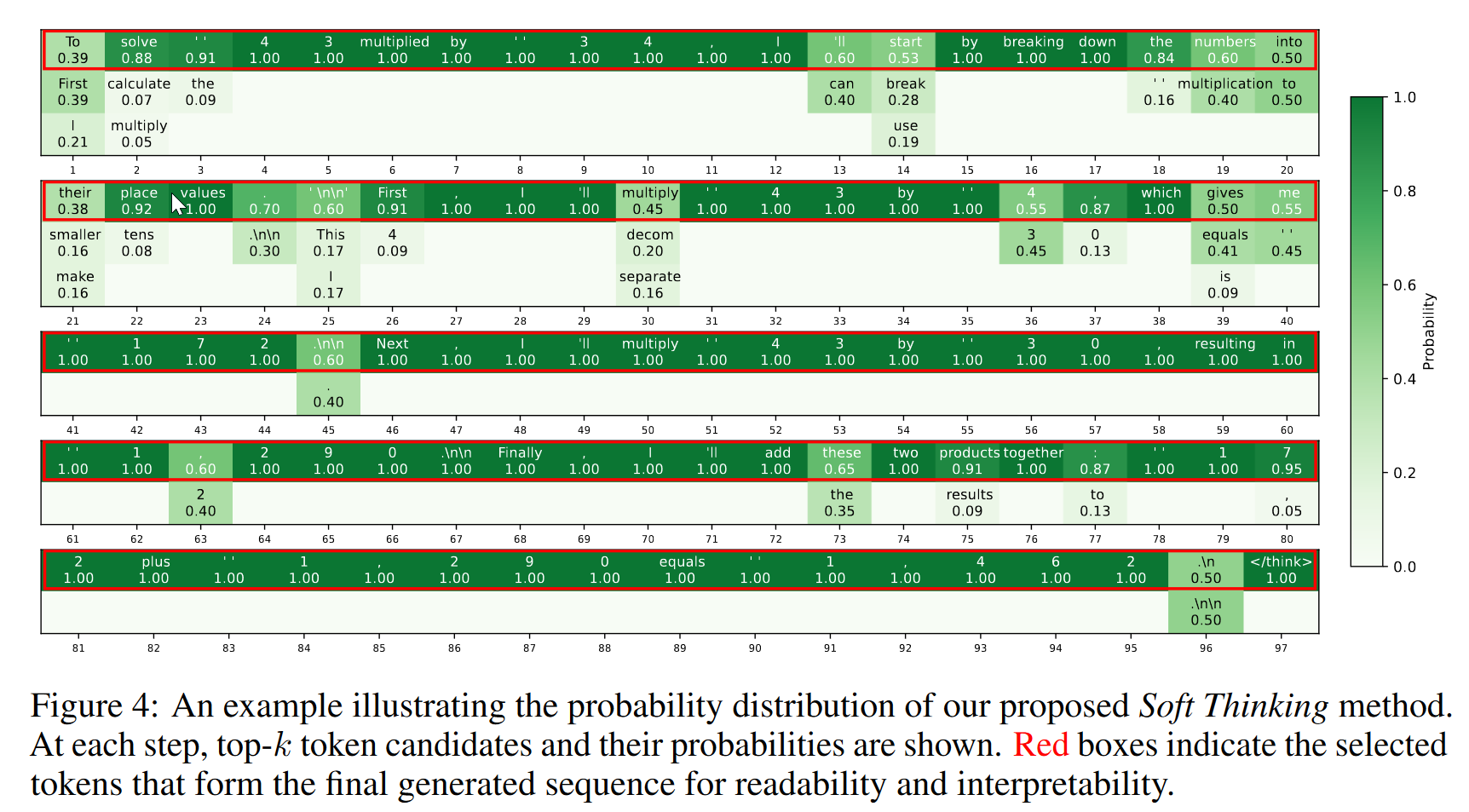 看token的概率分布,浅色的部分表明存在多种推理规划的路径。在计算的时候基本都是onehot向量。
看token的概率分布,浅色的部分表明存在多种推理规划的路径。在计算的时候基本都是onehot向量。
自己的感悟
- 这个continuous space reasoning与我们的idea强相关
- 这个idea很简单,效果还不错
- 缺点是只比较了CoT,不知道后面CoT优化的有没有比这篇工作效果更好的。
工作扩展
This line appears after every note.
Notes mentioning this note
250722 250729 阅读
数学推理
[[⭐⭐⭐⭐Arxiv’2505 Soft Thinking Unlocking the Reasoning Potential of LLMs in Continuous Concept Space]] :引入了Continuous Space Reasoning这一概念