⭐⭐⭐⭐⭐arxiv'2505 reasoning with omnithought a large cot dataset with verbosity and cognitive difficulty annotations
作者:Wenrui Cai1,2, Chengyu Wang2∗, Junbing Yan2, Jun Huang2, Xiangzhong Fang1
机构:上交大、阿里
文章理解
引言
- large reasoning models:o1、deepseek-R1 and QWQ-32B,擅长数学问题解决和代码生成
- CoT能够将复杂的问题打碎为中间步骤。SFT能让模型遵循显式的推理模式,RL通过迭代反馈和探索优化推理策略。 之前工作的缺点:
- LRM受限于大规模综合数据集,现在大部分是从开源社区的强大LRMs蒸馏所得。数量不足,或者缺乏多样性以及特性的描述。
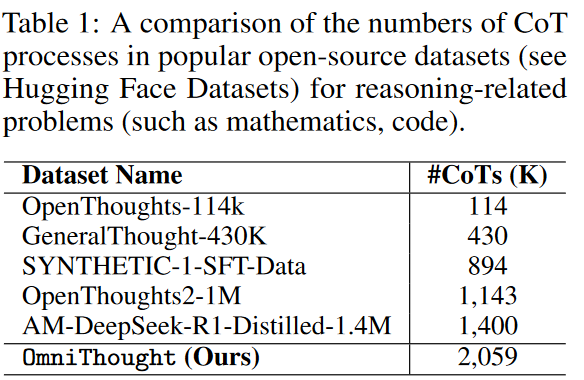
- Reasoning Verbosity(RV):对于一个问题是没有标答CoT的,很多思路都可以被标记为正确。但是使用过长的推理数据会影响表达
- Cognitive Difficulty (CD):希望用这个分数来表示这个问题与模型参数量的适配程度。分数越高表示这个问题很难想到,认知存在困难,适合参数量更大的模型。
解决方法:
论文贡献:
- 从数据角度,我们构建OmniThought,用2M个CoT 对,经过教师模型验证,并有对应的RV 和CD 分数
- 从方法角度,提出自动的pipeline创造数据集。
- 从模型角度,我们发布了一些在OmniThought上微调的LRM,拥有合适的推理长度,且在对应难度水平的推理上表现优秀。
相关工作
- 早期工作依赖专家的手工标注CoT过程,保证高质量的输出但是耗时耗力。
- 自动方法依赖LLM+prompt engineering生成推理步骤,但是受限于模型偏差需要额外的prompt设计
- 近期工作发现LRMs生成过长的CoTs会损害推理表现;请打的模型能够从详细的CoT获得增益,不那么强的模型能够在简单CoT监督上获得增益;有的还探索模式切换,即可以在正常输出和CoT推理之间切换如Qwen3
- 该工作表明,模型应该更具任务复杂度和模型认知能力(参数量)选择最佳的CoT
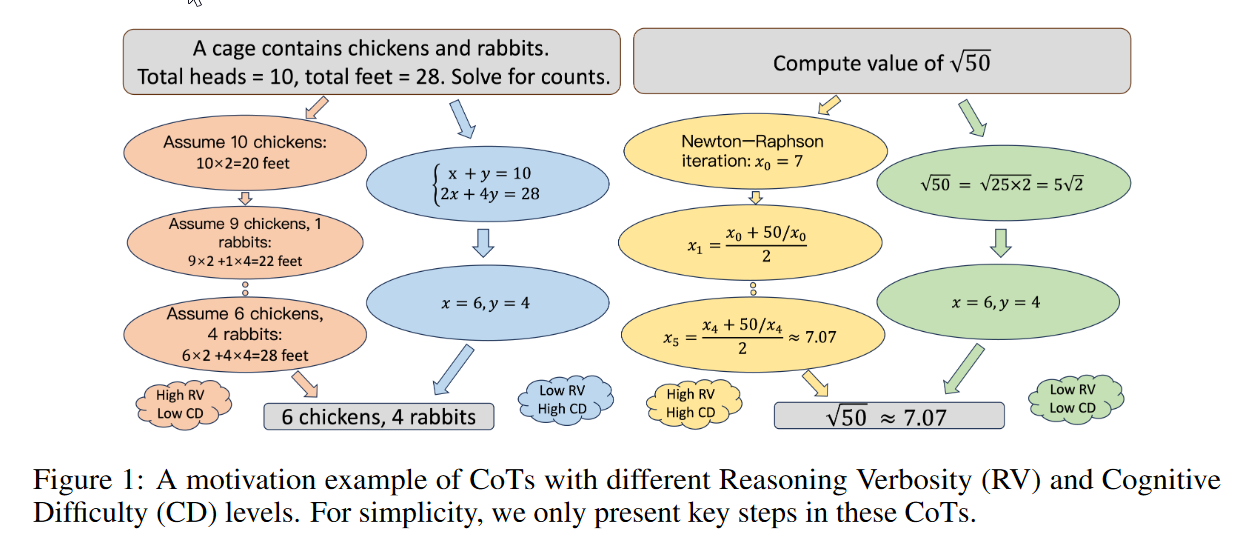
具体构建流程
- OpenThoughts21M and DeepMath-103K,用R1和QwQ-32B当做教室模型生成。前面说释放质量较低的COT过程也很有价值,因为它们可以支持DPO算法[21]或奖励模型培训[20]。因此,除非产生错误的答案,否则我们将该过程保留在数据集中。最后得到2 million CoT processes for 708K reasoning problems,每个问题至少两个正确CoT过程。
RV设计
CoT能够减少复杂任务的错误但是会导致在简单问题过度思考,浪费计算资源。所以CoT的长度应该对齐问题难度。
但仅靠词元数量来判断并不可靠。比如,一个推理过程可能步骤很多,但每一步都很简洁,那么总词元数可能不大,反之亦然。所以需要归一化。
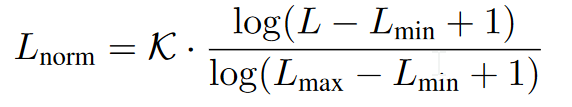
之后在和模型判断的得分(prompt engineering)进行加权融合。
Cognitive Difficulty设计
CoTs的难度应该与要训练的模型的认知能力保持一致。不同模型的认知和推理轨迹存在差异。
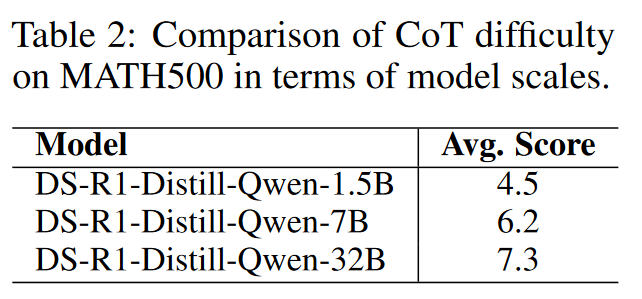
实验验证:让QwQ-32B根据回答的复杂度给出0-9的分数,每个过程测试三次。参数量大测模型明显偏高。
 用prompt engineering让模型给CoT过程打分。
用prompt engineering让模型给CoT过程打分。
可以根据基本模型的认知能力筛选数据集,从而最大程度利用现有数据。
进一步探索
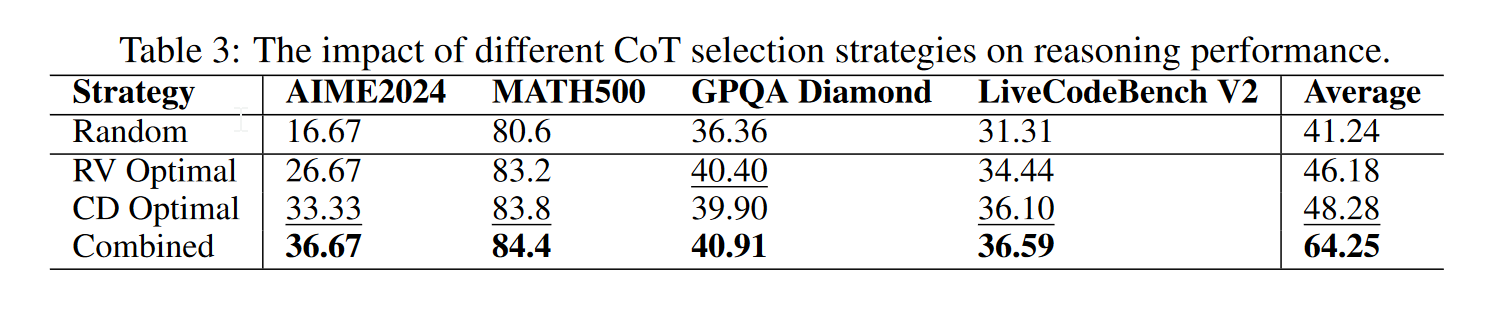
RV和CD谁重要
 We employ Qwen2.5-7B-Instruct as the base model, with an RV range of 3–5 and a CD range of 0–6。
We employ Qwen2.5-7B-Instruct as the base model, with an RV range of 3–5 and a CD range of 0–6。
这个数据集怎么给其他训练算法带来帮助 通过筛选特定分数的问题,能用更少的训练集带来相同甚至更好的效果。
实验
CoT选择
- RV是最优秀的
- CD适合模型参数量匹配的
如果CoT的难度小于等于当前模型的能力,则选中这些概率是均等的。难度超出得越多,选择概率越小。
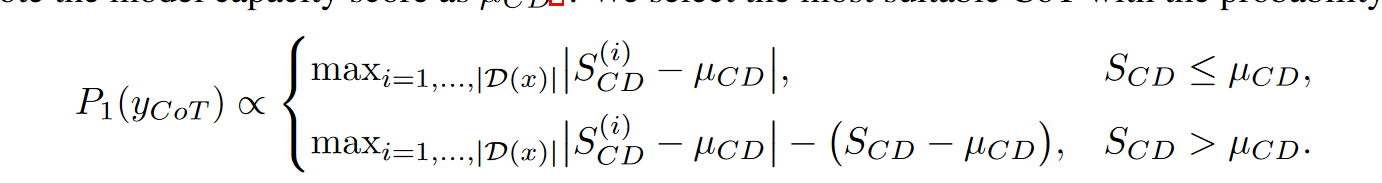
另外高CD的问题应该有高RV。如果不匹配,则需要惩罚。i代表了同个问题的第i种解题思路。
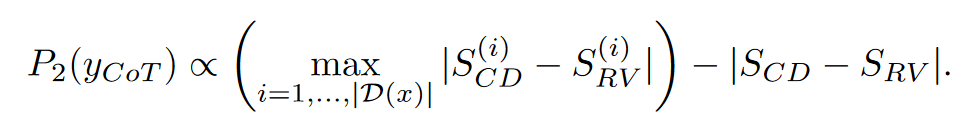
数据
使用Qwen2.5进行训练
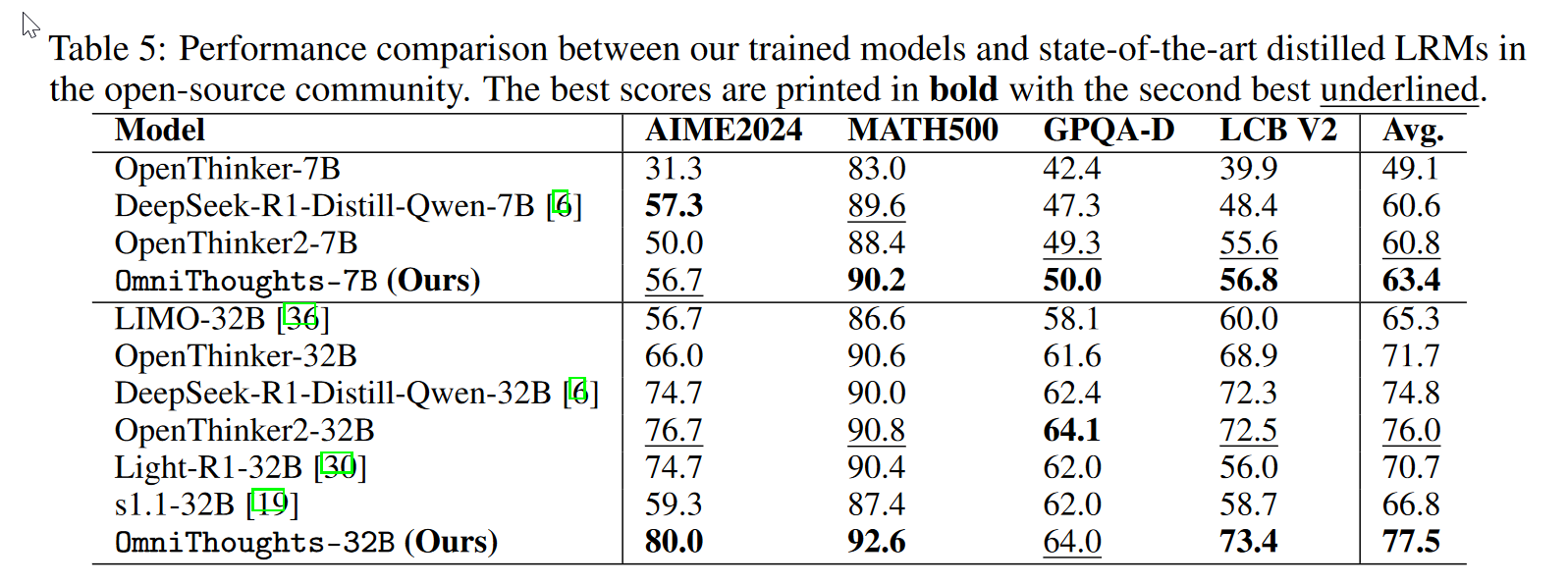 说明模型能力是和参数量有关,我们需要适当的选取CD与模型能力匹配的数据集进行训练。
说明模型能力是和参数量有关,我们需要适当的选取CD与模型能力匹配的数据集进行训练。
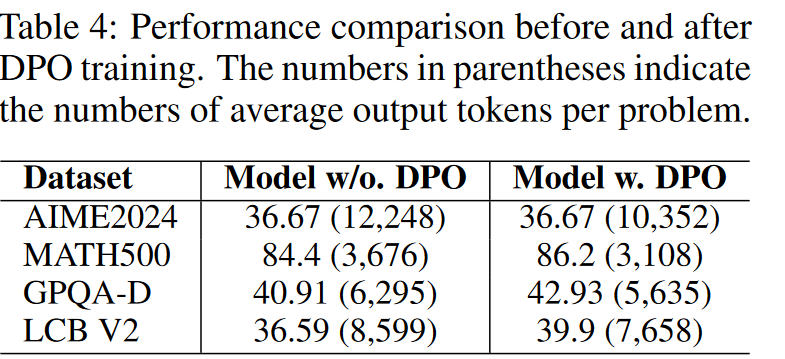
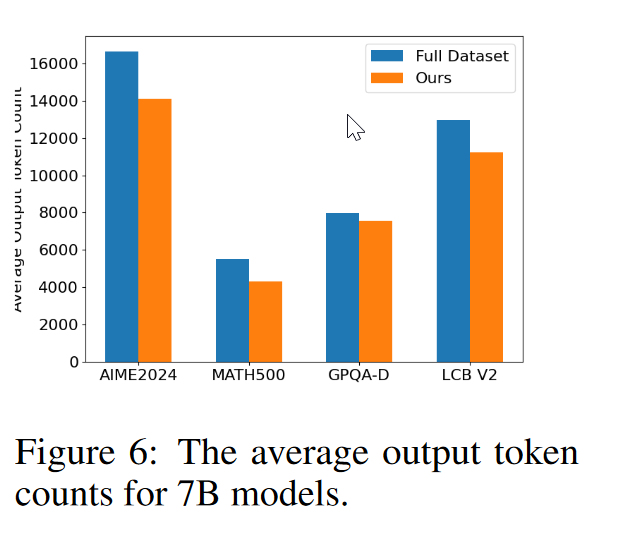
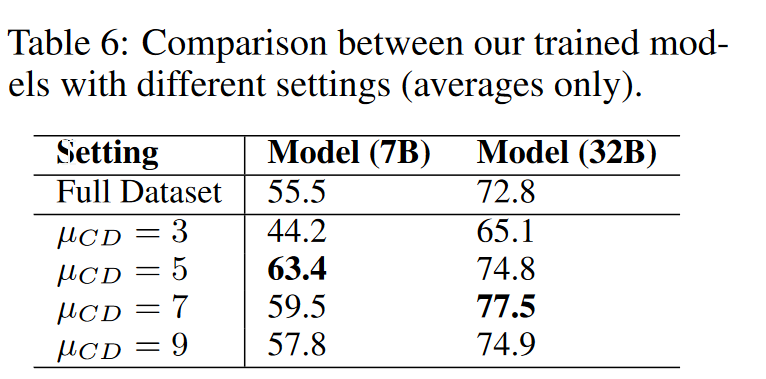 减少了推理token输出但是准确率得到提升。
减少了推理token输出但是准确率得到提升。
自己的感悟
- 每个想法都是用实验验证的,逻辑很好,实验也很充分。
- 这个benchmark分数标准的提出确实能够减少训练量也能达到相同的效果。就是缺乏可解释性,无论是LLM打分还是使用分数都是黑盒,前者使用prompt engineering,后者使用自己的经验,因为你不清楚7B或者32B对应多少CD分数。而且这个CoT选择概率也感觉怪怪的,公式中的-|SCD − SRV |并不常见。
工作扩展
- 如果中了可以参考这个方向发paper
This line appears after every note.
Notes mentioning this note
250709 250716 阅读
Math Reasoning
[[ICML’25 Forest-of-Thought Scaling Test-Time Compute for Enhancing LLM Reasoning]]