Arxiv'2501 ursa understanding and verifying chain Of Thought reasoning in multimodal mathematics
作者:Ruilin Luo12∗ Zhuofan Zheng2∗ Yifan Wang1 Xinzhe Ni1 Zicheng Lin1 Songtao Jiang3 Yiyao Yu1 Chufan Shi1 Ruihang Chu1 Jin Zeng2† Yujiu Yang1† 机构:清华 字节 浙大
文章理解
引言
之前工作的缺点:
- Process Reward Models通过Test-Time Scaling增强了LLM的能力,但是在多模态上的提升还未体现。之前的工作专注于训练math-intensive 视觉编码器,增强图文对齐或者用一些后训练策略(比如CoT)。
- 高质量推理数据的稀缺限制MLLM模型能力
- 没有合适的自动标记过程的技术在多模态文本上
- 在TTS中应用过程奖励模型,有可能进入奖励 hacking或者长度偏见,比如贪吃从原地打获得更高的存活得分。
[!NOTE] TTS是在测试LLM时,通过增加计算量来提升其性能的技术,而无需重新训练模型
论文贡献:
- 构建数据集MMathCoT-1M,一个多模态COT推理数据集,训练了URSA-8B;自动合成过程监督数据DualMath-1.1M
- 自动方法对于多模态上下文标签的持续存在
- 提出Process Supervision-GPRO减轻reward hacking和长度偏见
- 在六个多模态数据集做实验
具体工作
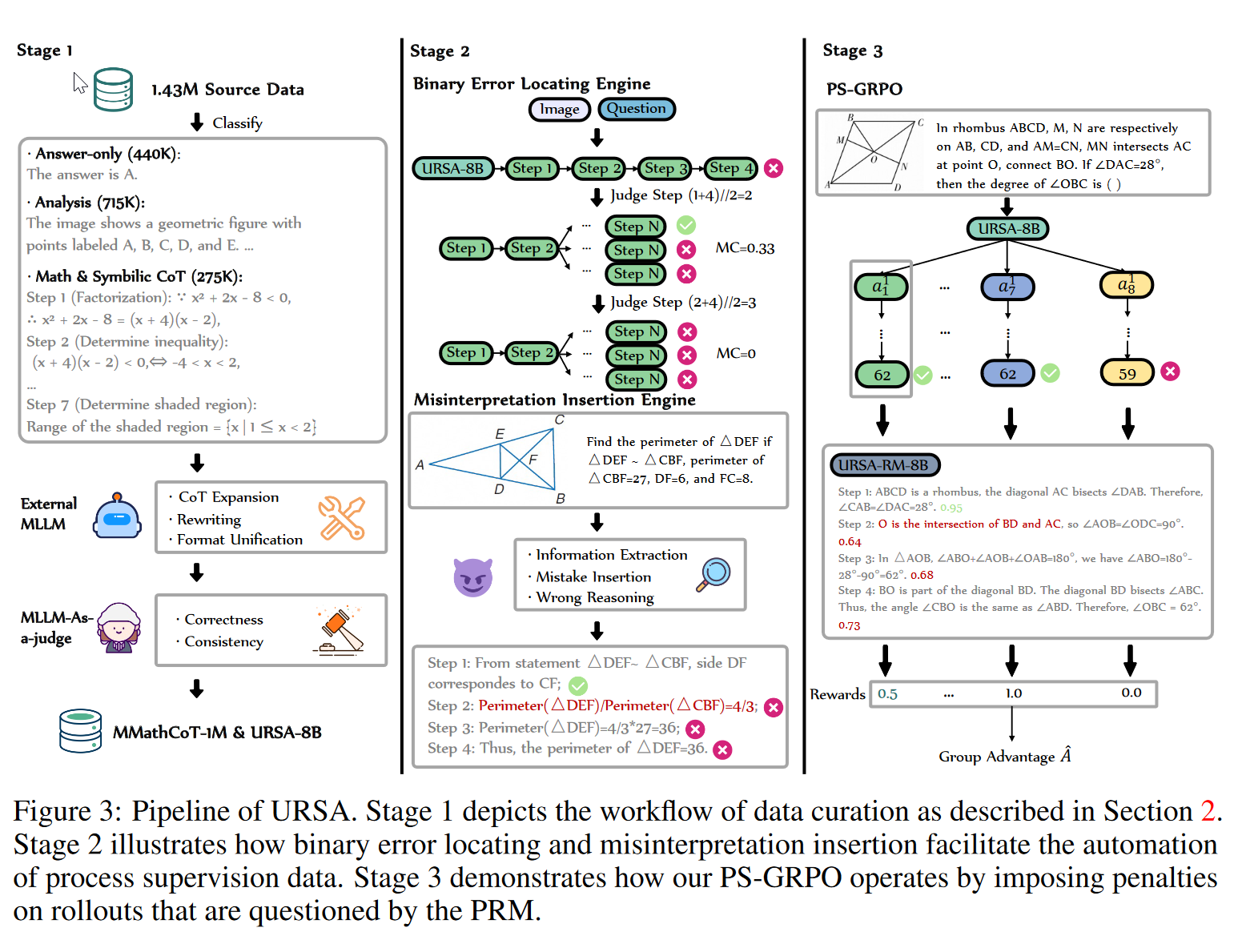
stage1
- 用LLaVA类似的结构,并收集视觉语言对齐数据。根据前人的经验,我们在对齐阶段只训练MLP的projector。(和我们工作想法类似,这里是怎么训练的?方便我们做多模态的简单训练)
- 数据集分类为answer-only, analysis-formatted, and CoTformatted三个策略,使用Gemni-1.5-Flash-002加上对应prompt,构建MMathCoT-1M
- MathV360K用prompt进行CoT扩展
- MAVIS-Geo, MAVIS-MetaGen [19], VarsityTutors [11], and Geo170K-QA [40]:重写分析,要求严格的step by step,同时内容丰富
- Multimath-EN-300K:严格的CoT格式
stage2
- Binary Error Locating Engine:计算蒙特卡洛估计值,如果大于0,则说明错误在后面的步骤,如果等于0,则是这个步骤出错,打上负标签。生成$S_{BEL}$
- 针对图像和文本感知不一致,我们引入Misinterpretation Insertion Engine插入幻觉。首先提出数学范式信息,其次要求模型将重点放在可能容易出错的条件上,用类似条件修改,最后,基于插入错误的步骤继续推理,并未后面的步骤分配负标签。生成$S_{MIE}$
- 合并两个数据集为DualMath-1.1M,训练模型URSA-8B-RM
stage3
-
outcome reward-based GRPO忽略了中间推理步骤的质量
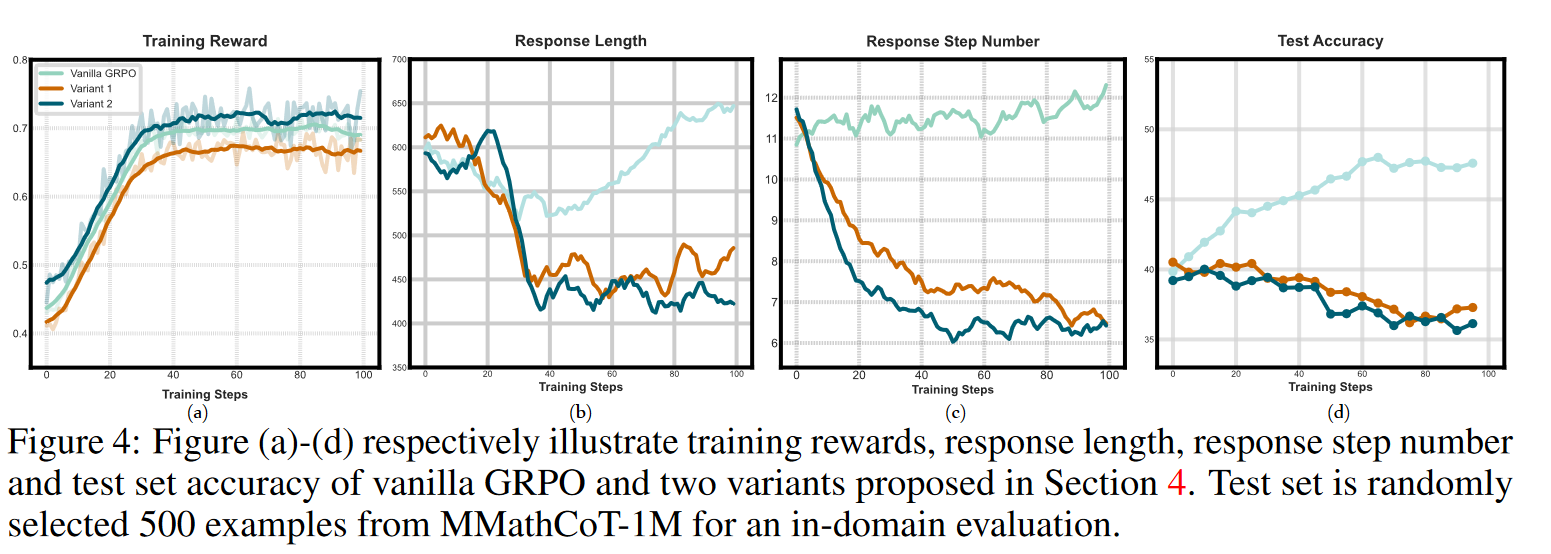
- 1:reward是结果奖励和平均过程奖励的和
-
2:结果奖励和标量过程奖励
- 准确率都降低,很快能到达标答,但是中间过程对并不一定能导致标答
- 模型越训练,回答越短,推理步骤越少。因为对于那些答案错误的例子,一旦推理过程中出现了第一个错误,那么在此之后的所有步骤基本都不可能再得到正确的结果了 。这导致了过程奖励模型(PRM)会很保守地给推理过程的后半段打出较低的奖励分数。这种机制反过来又会鼓励多模态大语言模型(MLLM)去进行更“被动”的推理,即不再深入思考,而是更依赖于对现有条件的模式识别或一些简单的直觉判断来得出答案,以避免因推理链条过长而受到“惩罚” 。
PS-GPRO:
- BoN performance + PRM错误识别能力
- drop-moment表示PRM质疑上述步骤的有效性,当连续步骤的reward下降时表明发生了drop-moment
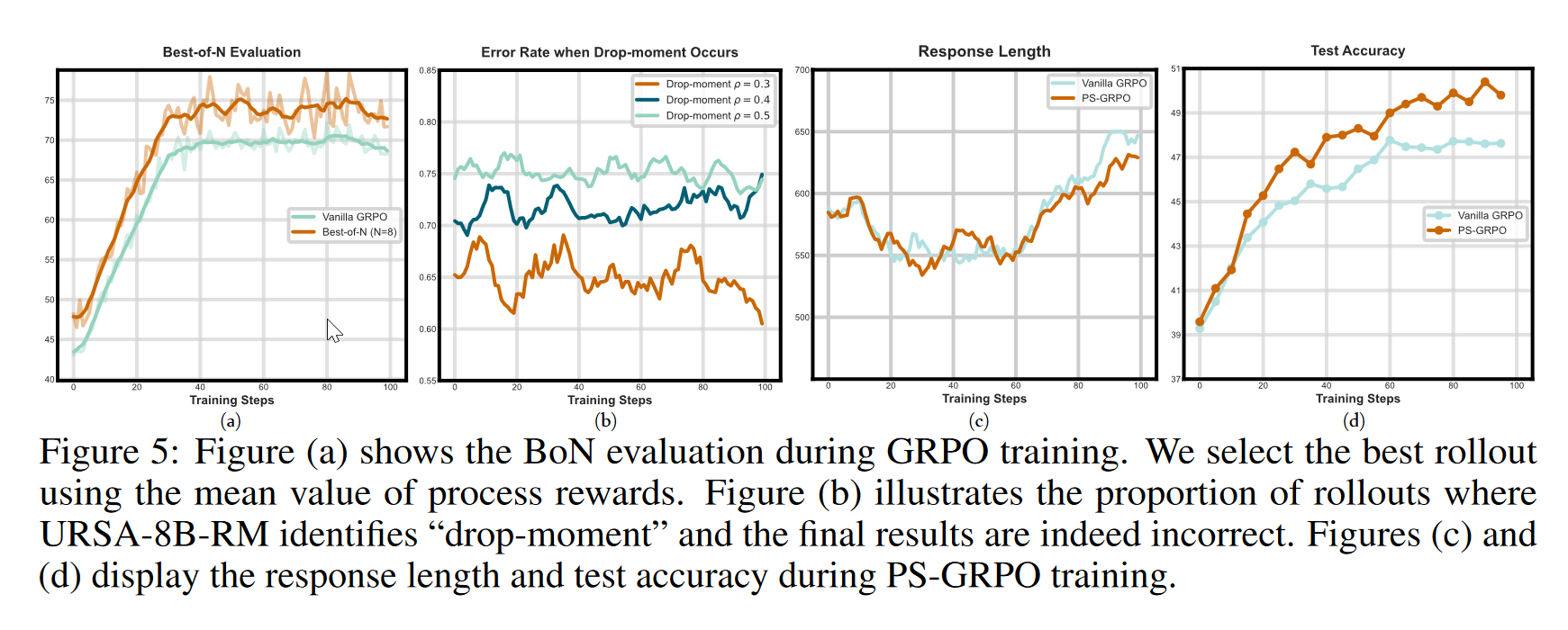
从图b可以看出,模型错误识别能力在很大程度上没有受损。尽管在线RL中PRM的标量奖励可能是不可靠的,但它显示的解决方案的相对质量相对可信赖。设置奖励为,避免了奖励影响到了长度偏见:
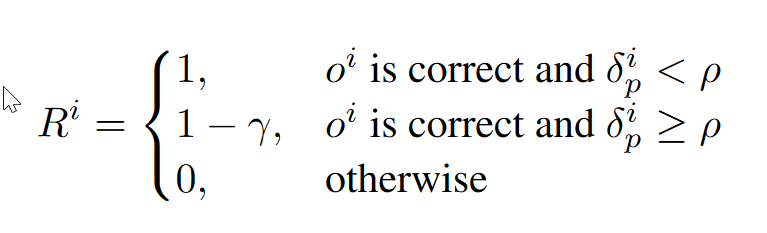
实验
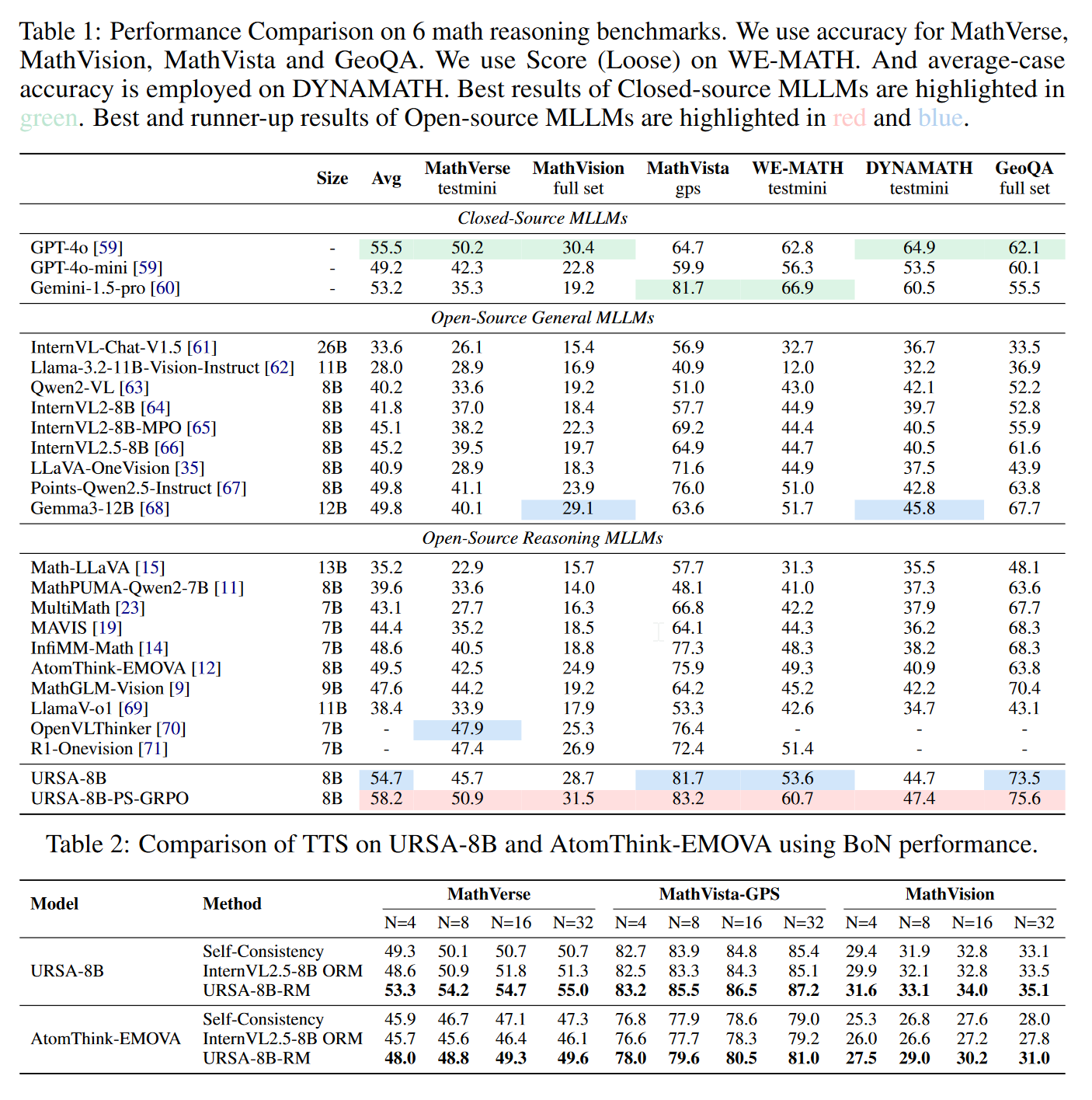
消融实验
自己的感悟
- 这篇工作增强了数据集,之后构建了新的强化学习奖励来解决PRM中reward hacking的问题。实验很充分,既有SOTA又有消融。
工作扩展
- 后续可以尝试复现
This line appears after every note.
Notes mentioning this note
250709 250716 阅读
Math Reasoning
[[ICML’25 Forest-of-Thought Scaling Test-Time Compute for Enhancing LLM Reasoning]]