⭐ ⭐ ⭐ ⭐ ⭐ arxiv 2311' llm_survey_chinese
时间:24.1.8
1.引言
Static LM➡️ Network LM ➡️Pre-trained LM ➡️ Large LM
PLM:预训练一个网络捕捉上下文的感知词表示。 LLM:扩展模型大小或数据大小获得涌现能力。
IR领域正在受到聊天机器人ChatGPT所带来的新挑战。New Bing展示了一个初步的增强搜索结果的尝试。
本综述从四个主要方面对 LLM 的最近进展进行文献综述,包括预训练(如何预训练出一个有能力的 LLM)、适配微调(如何从有效性和安全性两个角度有效地微调预训练的 LLM)、使用(如何利用 LLM 解决各种下游任务)以及能力评估(如何评估 LLM 的能力和现有的经验性发现)。
2.概述
2.1 涌现能力
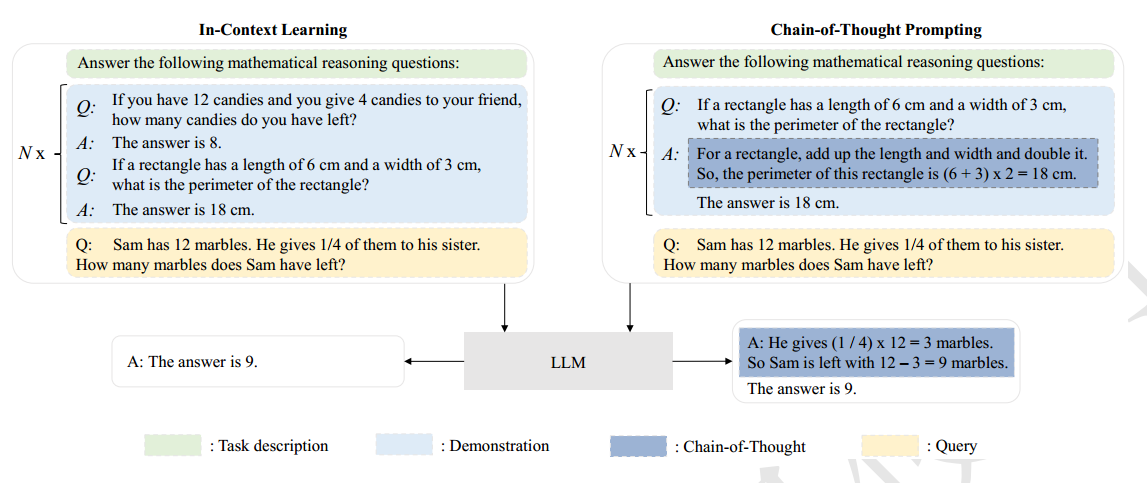
- 上下文学习(类比学习):根据给出的示例完成填空
- 指令微调:自然语言数据集上微调,使其在未见过的任务上也有较好表现
- 逐步推理:CoT(思维链)
3. 模型资源
3.1 公开可用的API
CodeGen(11B)是一个为生成代码设计的自回归语言模型,需要LLM获得足够的编程知识。
3.2语料库
3.3python代码库资源
4.预训练
4.1数据收集
4.1.1 数据来源
鉴于 LLM 所展现出的惊人泛化能力,有研究将预训练语料库扩展到更专用的数据集,如多语言数 据、科学数据和代码等,以此来赋予 LLM 解决专用任务的能力 [34, 56, 91]。
数学符号和蛋白质序列,通常需要特定的标记化和预处理技术来将这些不同格式的数据转换为可以被语言模型处理的统一形式。
编写的程序可以成功通过专家设计的单元测试用例 [78] 或解决竞赛编程问题 [111]。最近的一项研究 [46] 还推测,训练代码可能是复杂推理能力(例如 CoT 能力 [32])的来源。此外,将推理任务格式化为代码的形式还可以帮助 LLM 生成更准确的结果 [156, 157]。
4.1.2数据预处理
质量过滤:基于度量的过滤:可以利用生成文本的评估度量,例如困惑度(perplexity),来检测和删除不自然的句子。
4.1.3 预训练数据
预训练数据的数量:建议研究人员在充分训练模型时,尤其是在调节模型参数时,应该更加关注高质量数据的数量。
4.2架构
4.2.1主流架构
编码器-解码器架构:编码器采用堆叠的多头自注意层对输入序列进行编码以生成其潜在表示,而解码器对这些表示进行交叉注意并自回归地生成目标序列。目前,只有少数LLM 是基于编码器-解码器架构构建的,例如 Flan-T5。
因果解码器架构(仅解码器):因果解码器架构采用单向注意力掩码,以确保每个输入 token 只能关注过去的 token 和它本身。输入和输出 token 通过解码器以相同的方式进行处理。代表模型GPT-3。
前缀解码器架构:前缀解码器架构 (也称非因果解码器架构) 修正了因果解码器的掩码机制,以使其能够对前缀 token 执行双向注意力 [169], 并仅对生成的 token 执行单向注意力。这样,与编码器-解码器架构类似,前缀解码器可以双向编码前缀序列并自回归地逐个预测输出 token, 其中在编码和解码过程中共享相同的参数。实用的建议是不从头开始进行预训练,而是继续训练因果解码器,然后将其转换为前缀解码器以加速收敛[29],例如 U-PaLM [115] 是从 PaLM [56] 演化而来。
4.2.2详细配置
层标准化 (Layer Norm, LN) [172] 被广泛应用于Transformer 架构中。LN 的位置对 LLM 的性能至关重要。虽然最初的 Transformer [22] 使用后置 LN,但大多数 LLM采用前置 LN 以实现更稳定的训练,尽管会带来一定的性能损失 [181]。
激活函数:为了获得良好的性能,在前馈网络中也需要设置合适的激活函数。在现有的 LLM 中,广泛使用 GeLU 激活函数 [183]。
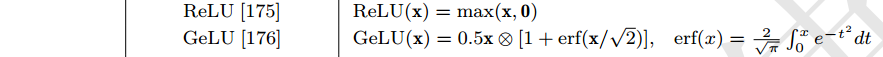
位置编码:由于 Transformer 中的自注意模块具有置换不变性,因此需要使用位置编码来注入绝对或相对位置信息以建模序列。在经典的 Transformer [22] 中有两种绝对位置编码的变体,即正弦函数和学习的位置编码,后者通常在 LLM 中使用。
4.2.3 预训练任务
语言建模:语言建模任务 (LM) 是预训练仅包含解码器的LLM (如 GPT3 [55] 和 PaLM [56]) 最常用的目标。给定一个token 序列 $\mathbf{x}={x_1,\ldots,x_n}$, LM 任务旨在基于序列中前面的 token $x_{<i}$, 自回归地预测目标 token $x_i$。通常的训练目标是最大化以下似然函数:
\[\mathcal{L}_{LM}(\mathbf{x})=\sum_{i=1}^n\log P(x_i|x_{<i}).\]去噪自编码:除了传统的 LM 之外,去噪自编码任务 (DAE) 也被广泛用于 PLM [24,87]。DAE 任务的输人 $x_{ \tilde{x} }$ 是一些有随机替换区间的损坏文本。然后,训练语言模型以恢复被替换的 token $\tilde{\mathbf{x}}$。
4.3模型训练
3D并行:数据并行,流水线并行,张量并行
数据并行:将模型参数和优化器状态复制到多个GPU上,再分配训练训练语料库。不同GPU上计算的梯度进一步聚合来获得整个批量的梯度。
流水线并行:将 LLM 的不同层分配到多个 GPU 上。然而,流水线并行的朴素实现可能导致 GPU 利用率降低,因为每个 GPU 必须等待前一个 GPU 完成计算,从而导致不必要的气泡开销。
张量并行:旨在为多GPU 加载而分解 LLM。与流水线并行不同,张量并行专注于分解 LLM 的张量(参数矩阵)。对于 LLM 中的矩阵乘法操作 Y = XA,参数矩阵 A 可以按列分成两个子矩阵 A1 和A2,从而将原式表示为 Y =[XA1, XA2]。通过将矩阵 A1和 A2 放置在不同的 GPU 上,矩阵乘法操作将在两个 GPU上并行调用,并且可以通过跨 GPU 通信将两个 GPU 的输出组合成最终结果。
混合精度训练: 以前的PLM(例如BERT[ 23] ) 主要使用 32位浮点数(FP32) 进行预训练。近年来,为了预训练极大的语言模型,一些研究 [196] 开始利用 16 位浮点数 (FP16), 以减少内存使用和通信开销。此外,由于流行的 NVIDIA GPU(例如 A100) 具有的 FP16 计算单元是 FP32 的两倍,FP16 的计算效率可以进一步提高。然而,现有的研究发现,FP16 可能导致计算精度的损失 [59,69], 影响最终的模型性能。
虽然会损失一些模型性能,但量化语言模型具有更小的模型大小和更快的推理速度 [97, 205, 206]。 对于模型量化,INT8 量化是一个流行的选择 [205]。此外,一些研究工作尝试开发更激进的 INT4 量化方法 [97]。
6.使用
作为两种典型的方法,Auto-CoT [261] 利用 LLM 使用零样本提示 “Let’s think step by step” 来生成中间推理步骤,而least-to-most 提示 [262] 首先询问 LLM 来执行问题分解,然后利用 LLM 根据先前解决的中间答案依次解决子问题
6.2 CoT 思维链提示(提升推理)
思维链(Chain-of-Thought,CoT)[32] 是一种改进的提示策略,旨在提高 LLM 在复杂推理任务中的性能,例如算术推理[273–275],常识推理[276,277] 和符号推理 [32]。
由于 CoT 是一种涌现能力 [47],它只能有效增强有 100 亿或更多参数的足够大的模型 [32],而对小模型无效。
总的来说,CoT 提示提供了一种通用而灵活的方法来引出 LLM 的推理能力。还有一些工作尝试将这种技术扩展至多模态任务 [288] 和多语言任务 [289]。除了直接通过 ICL 和CoT 使用 LLM,最近还有一些研究探索了如何将 LLM 的能力专业化于特定任务 [290–292],这被称为模型专业化(model specialization)[293]。例如,在 [293] 中,研究人员用 LLM 生成推理路径,然后再用这些推理路径微调小规模的语言模型Flan-T5 [64],从而将 LLM 的数学推理能力专业化。模型专业化可以应用于解决各种任务,如问答 [294]、代码生成 [295]和信息检索 [296]。
7.能力评测
对于模型的专业化至关重要。然而,将这种专业知识注人到LLM 中并不容易。正如最近的一些分析[46, 378] 所讨论的, 当训练 LLM 展现特定的能力,以使模型在某些领域获得出色的表现时,它们可能会在另外一些领域遇到困难。这种问题与神经网络训练中的灾难性遗忘 [379,380] 有关,它指的是整合新旧知识时发生冲突的现象。类似的情况也出现在 LLM 的人类对齐微调中,要将模型向人类的价值观和需求对齐,必须要支付“对齐税”[61] (例如可能在 ICL 能力上产生损失)。因此,开发有效的模型专业化方法至关重要,以使得 LLM 可以灵活地适配到各种任务场景,并尽可能保留其原有的能力。
数学推理:数学推理任务需要综合利用数学知识、逻辑和计算来解决问题或生成证明过程。现有的数学推理任务主要可分为数学问题求解和自动定理证明两类。对于数学问题求解任务,常用的评估数据集包括 SVAMP [274]、GSM8k [273] 和MATH [312] 数据集,其中 LLM 需要输出准确的具体数字或方程来回答数学问题。由于这些任务也需要多步推理,CoT 提示策略已被广泛采用来提高 LLM 的推理性能 [32]。作为一种实用的策略,持续在大规模数学语料库上预训练 LLM 可以大大提高它们在数学推理任务上的性能 [34,147,397]。此外,由于不同语言中的数学问题共享相同的数学逻辑,研究人员还提出了一个多语言数学问题基准测试[289],用于评估 LLM 的 多语言数学推理能力。另一个具有挑战性的任务是自动定理证明 (ATP) [362,364,398], 要求用于推理的模型严格遵循推理逻辑和数学技能。为了评估在此任务上的性能,PISA [363] 和 miniF2F [364] 是两个典型的 ATP 数据集,其中证明成功率是评估指标。作为一种典型的方法,现有的 ATP 上作利用LLM 来辅助交互式定理证明器 (interactive theorem prover,ITP, 例如 Lean、Metamath 和 Isabelle) 进行证明搜索 [399- 401]。ATP 研究的一个主要限制是缺乏相关的形式化语言语料库。为了解决这个问题,一些研究利用 LLM 将非形式化的表述转换为形式化证明以增加新数据 [157], 或者生成草稿和证明草图以减少证明搜索空间 [402]。
This line appears after every note.