Acl'25 a survey of mathematical reasoning in the era of multimodal large language model benchmark, method & challenges
作者:Yibo Yan1,2, Jiamin Su1, Jianxiang He1, Fangteng Fu1, Xu Zheng1,2, Yuanhuiyi Lyu1,2, Kun Wang3, Shen Wang4, Qingsong Wen4, Xuming Hu1,2,* 机构:HKUST(GZ)
文章理解
引言
visual elements in mathematical problem: diagrams,graphs or eqations
之前的工作:
- 专注于某个方面,比如强化学习在数学推理上,或者定理证明,从而忽视了LLM带来的进步
- 其他的文章有探讨LLM,但是没有探讨多模态LLM
相关工作
Math-LLM的进展:
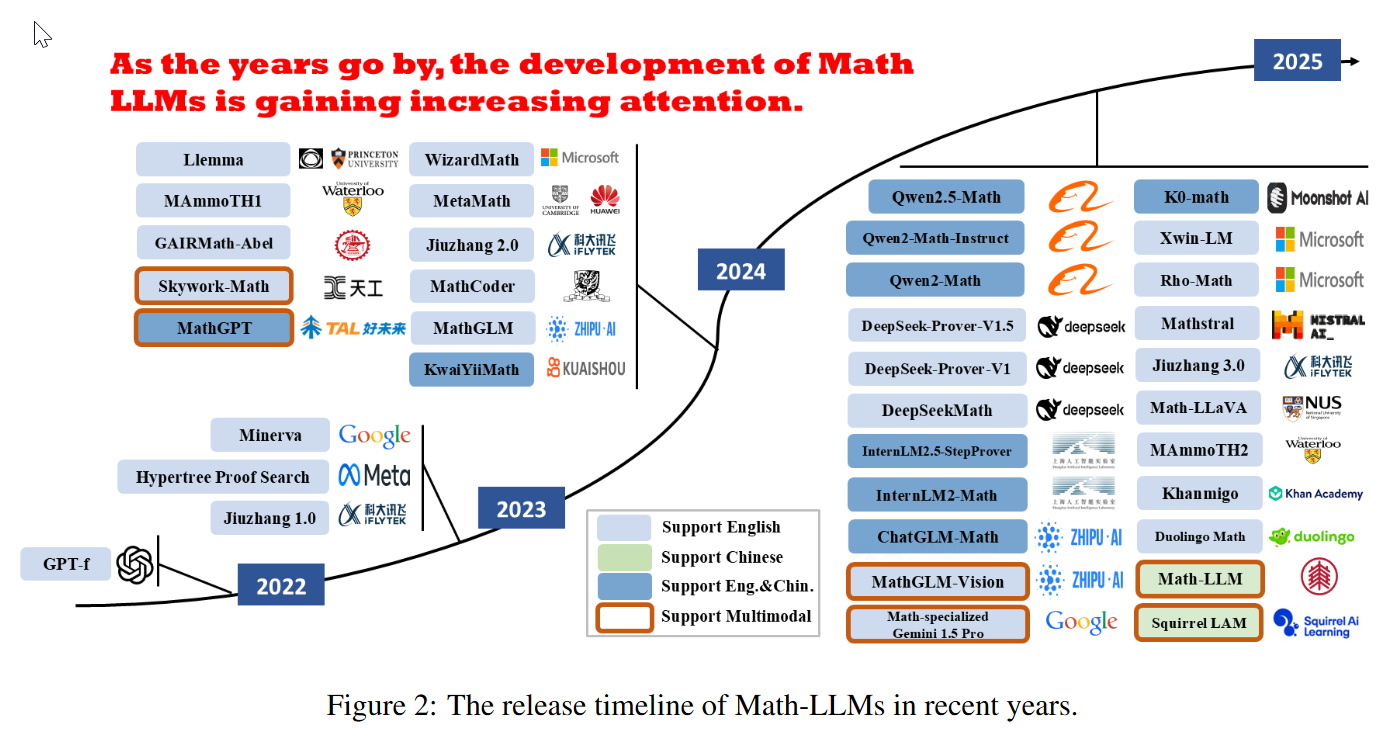
Benchmark
Dataset:

Task
模型选择:GPT-4o Gemini-pro-1.5 任务类型:
- 帮助学生认识和纠正错误
- 证明任务需要逻辑思考和系统的解决问题的能力
Evaluation
- Discriminative Evaluation:让MLLM正确辨别或选择正确答案
- Generative Evaluation:需要MLLM输出详细的解题步骤,有的让GPT-4作为评分者
Training Data
scale: variety:
典型模型
- G-LLaVA:从几何图片提取是视觉特征,并通过文本描述共同对它们进行性建模,使得模型理解关键元素 点线面
- MAVIS:自动快速生成大尺度 高质量的多模态数学数据集
- Math-LLaVA
方法论
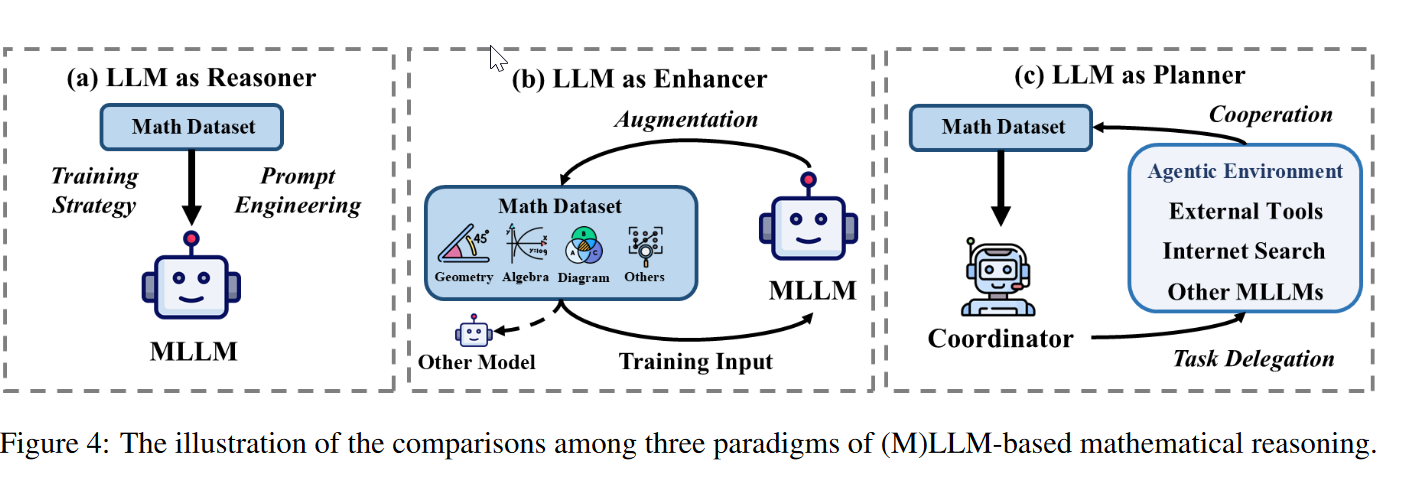
文章数量:Reasoner > Enhancer > Planner (multi-agent也许可以帮助更好扮演)
- LLM as a Reasoner
- LLM as a Enhancer:为数据集增加噪声或生成问题变体
- LLM as a Planner:比如使用外部工具如matplotlib生成中间草图帮助推理
挑战
- 数据质量:数据集专注于问题回答,缺乏跟踪步骤或证明注释;合成数据集出现类别偏差
- 视觉推理不足:可能需要想办法增强视觉理解模块
- 音频、视频或交互式推理数据集不足
- 数据集类别不足
- 错误反馈有限,MLLM缺乏机制有效地修改错误
- 和教育结合
- Test-time Scaling
- 比如GPT-4,模型在实际运行(测试)的时候,能够根据输入的不同,动态地调整自己的结构或者使用的资源。比如,一个模型可能根据问题的难易程度,决定是使用一个小型、快速的网络还是一个大型、更复杂的网络来处理。
- 什么时候优先符号计算而不是视觉解析
- 开发模态感知缩放控制器,自己调整内部结构和计算流程
- 轻量级元优化层:能够进行“二次优化”的层,MoE 系统中的专家选择
自己的感悟
- 综述工作量还是很大的,重要的是怎么把看过的论文以一些子标题组织起来,再结合图表来理解。
- 读起来很通顺,丝毫不卡顿,除了某些专有名词比如Test-Time Scaling
工作扩展
This line appears after every note.
Notes mentioning this note
250701 250708 阅读
Prefix Tuning
[[ICML’23 BLIP-2 Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models]]