⭐⭐⭐⭐acl'24 champ a competition Level dataset for fine Grained analyses of llms’ mathematical reasoning capabilities
作者:Yujun Mao、 Yoon Kim 、 Yilun Zhou
机构:波士顿大学 MIT、salesforce
文章理解
引言
之前工作的缺点:
- LLM的数学能力提升依赖于参数量的提高、负责的prompt提示如CoT;或者引用外部的计算器于代码解释器。缺乏探索外部概念和提示如何影响能力。
论文贡献:
- 用实验验证一些观点,得出两个结论
- 一个模型可能在错误的推理路径下得到正确的答案
- 大部分model验证他们的解法是比较困难的
相关工作
- competition-level problems:MATH,对于公式的应用并没有那么直白
- CHAMP:我们注释相关的概念和提示,并在每个解决步骤上进一步标记它们。比如允许在上下文引入额外的注释信息。
- 我们的数据集包含第一个出现错误的步骤解析,可以用来验证模型在指定回答上的验证效果。
- PRM800K:MATH ,每个步骤标记为正确 不正确和中性
- FELM:GSM8K和MATH 400道题目的注释
- 前两个通过众包来标注,我们数据集通过多种模型混合生成
- 论文想法和LLM如何理解不同文本是一致的。
- 较大参数量的模型会抵制吸收与训练过程不一样的知识
- 本篇论文是为了探索不同方式英雄LLM的行为
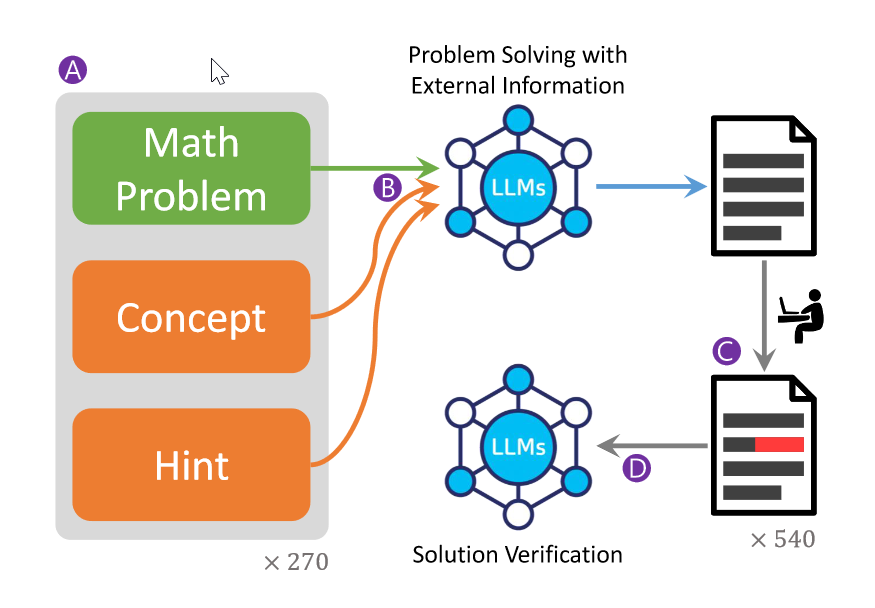
CHAMP的构建
- 问题来自Problem-Solving Strategies by Engel,高中数学竞赛的经典。改写将其中证明题改为可验证最终答案的题目。270道题目:number theory (80), polynomial (50), sequence (50), inequality (50) and combinatorics (40).
- 注释概念和提示:概念是等式或定理,提示是特定题目的解题技巧和策略。同时还标注了category、name、parent concept
- First wrong step (FWS) annotations:分析LLM生成的解法识别客观错误。
实验
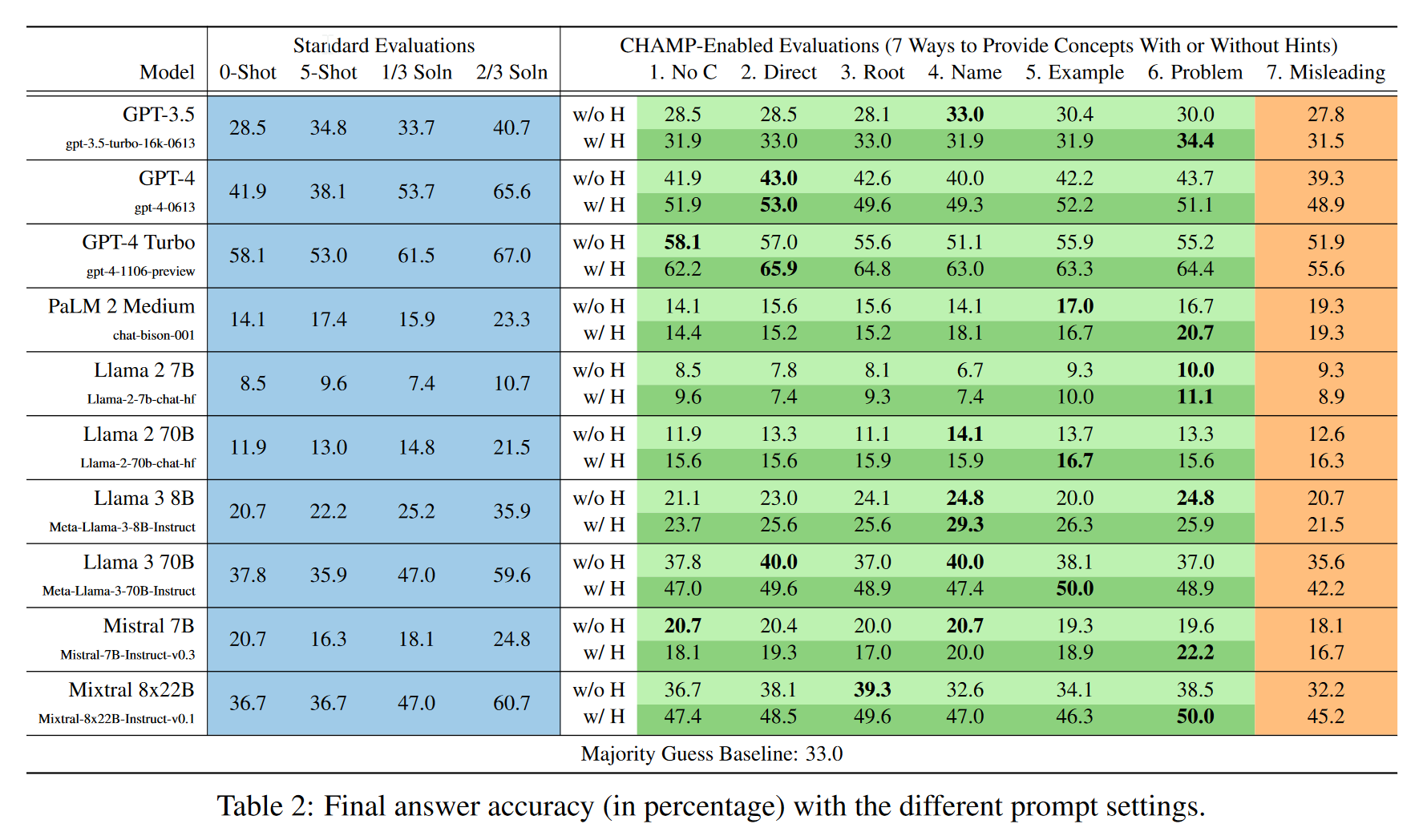
- 蓝色部分:给了部分解法是有帮助的。GPT似乎并不需要上下文提示
- 绿色部分,六种不同引入Concept的方法。提供concept有时可能有害,可能是因为和训练预料相矛盾。对于参数量多的模型,给hint能够显著提升;相反参数量少的提升不多。
- No C
- 直接把概念放在prompt
- 加入root concept即概念对应的root父概念
- 利用新对话检索concept的信息
- 利用新对话提供一个这个concept的例子
- 提供一个使用该概念的示例问题及step by step 解决方案
- 橙色类别:misleading用同类别,但不同root父概念的概念进行随机替换。
- 大部分下降,除了PaLM2 表明他们并不能很好地利用提供的信息
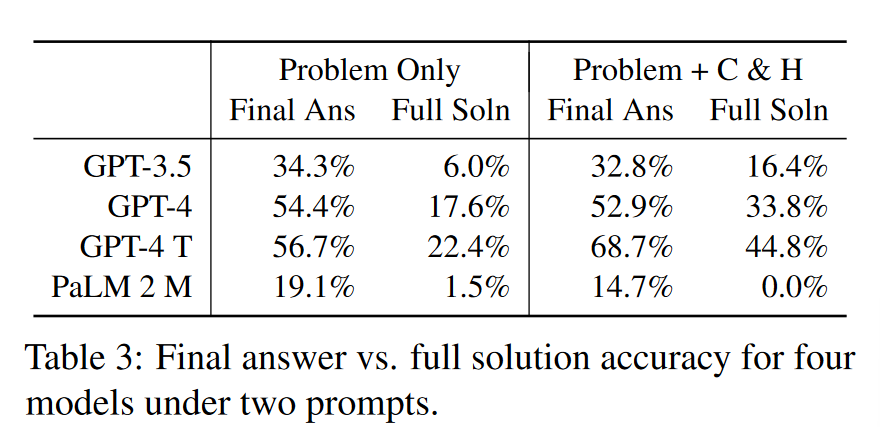
表明只看final answer accuracy是不够的,对于full solution accuracy仍然存在问题。会夸大模型能力
解决方案验证
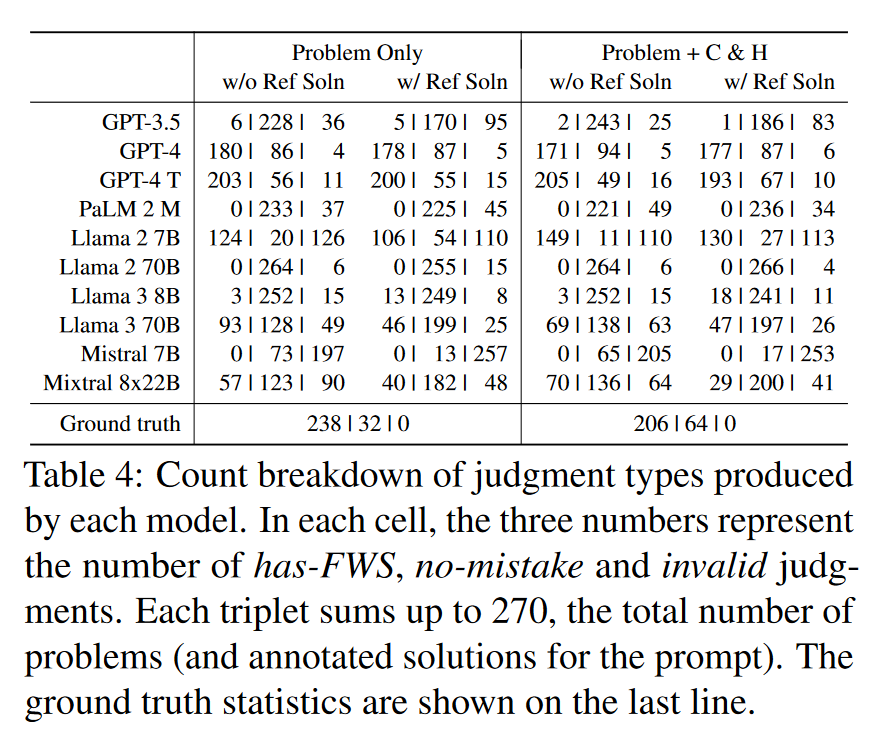
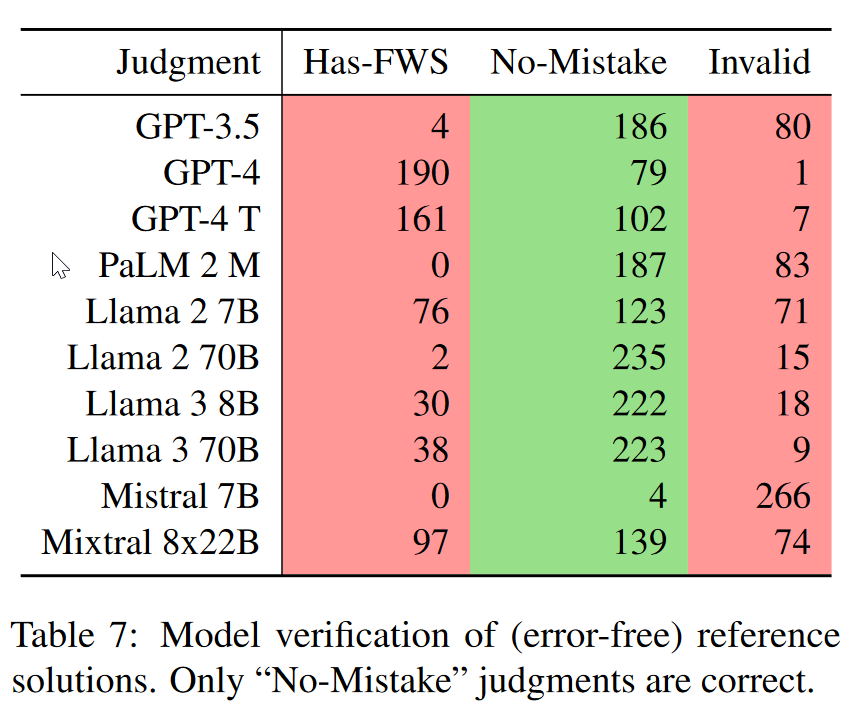
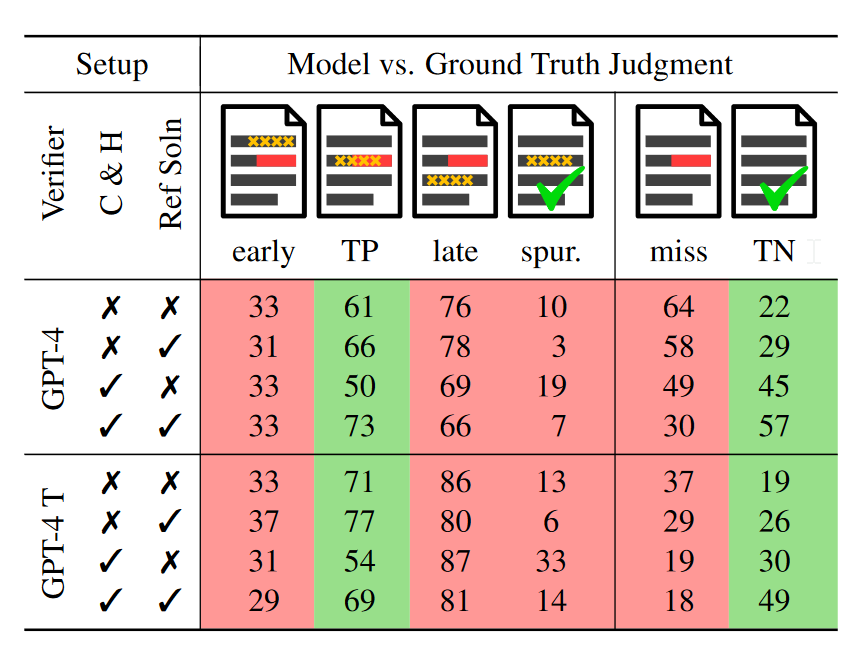 将GT当做学生答案,让模型评判,大部分模型表现得较好,是由于他们没有对应的评判能力,所以一昧地输出No-mistake。
将GT当做学生答案,让模型评判,大部分模型表现得较好,是由于他们没有对应的评判能力,所以一昧地输出No-mistake。
自己的感悟
- 是一篇实验充分的讨论性文章,没有提出太多新颖的东西,但是用自己创造的dataset验证了很多idea。
- 可以看出不同参数的模型利用Concept和Hint的能力不同,同时模型在判断正误的能力上仍然需要进步。启发我们的就是我们提出的利用Q-former类似的结构加入的额外信息能否像这里的hint和concept一样起效果。
- 但是由于时代进步,MATH相对简单,同时model已经进化了一个level了,这个概念是否正确是存疑的。
工作扩展
- 可以在新的模型上复现效果验证论文猜想。
This line appears after every note.
Notes mentioning this note
250709 250716 阅读
Math Reasoning
[[ICML’25 Forest-of-Thought Scaling Test-Time Compute for Enhancing LLM Reasoning]]